ABSTRAK
Meskipun ada kemajuan signifikan dalam klasifikasi gambar, model pembelajaran mendalam kesulitan untuk secara akurat membedakan detail halus dalam gambar, menghasilkan prediksi yang terlalu percaya diri dan tidak seimbang untuk kelas tertentu. Model-model ini biasanya menggunakan teknik kalibrasi ulang fitur tetapi tidak memperhitungkan ketidakpastian yang mendasari dalam prediksi—terutama dalam tugas berurutan yang kompleks seperti klasifikasi gambar. Ketidakpastian ini dapat secara signifikan memengaruhi keandalan analisis berikutnya, yang berpotensi mengorbankan akurasi di berbagai aplikasi. Untuk mengatasi keterbatasan ini, kami memperkenalkan Modul Kalibrasi Ulang Persamaan Diferensial Stokastik (SDERM), pendekatan baru yang dirancang untuk secara dinamis menyesuaikan respons fitur berdasarkan saluran dalam jaringan saraf konvolusional. Ini mengintegrasikan kerangka persamaan diferensial stokastik (SDE) ke dalam modul kalibrasi ulang fitur untuk menangkap ketidakpastian yang melekat dalam data dan prediksi modelnya. Sejauh pengetahuan kami, studi kami adalah yang pertama mengeksplorasi integrasi modul kalibrasi ulang fitur berbasis SDE dalam klasifikasi gambar. Kami membangun SDERM berdasarkan dua jaringan yang saling berhubungan—jaringan drift dan difusi. Jaringan drift berfungsi sebagai komponen deterministik yang mendekati fungsi prediktif model yang secara sistematis memengaruhi kalibrasi ulang prediksi tanpa mempertimbangkan keacakan. Bersamaan dengan itu, jaringan difusi menggunakan proses Wiener yang menangkap ketidakpastian inheren dalam data dan prediksi jaringan. Kami menguji akurasi klasifikasi SDERM dalam ResNet50, ResNet101, dan ResNet152 terhadap modul kalibrasi ulang lainnya, termasuk Squeeze-Excitation (SE), Convolutional Block Attention Module (CBAM), Gather and Excite (GE), dan Position-Aware Recalibration Module (PARM), serta arsitektur Bottleneck asli. Kumpulan data klasifikasi citra publik digunakan, termasuk CIFAR-10, SVHN, FashionMNIST, dan HAM10000, dan akurasi klasifikasinya dievaluasi menggunakan skor F1. Arsitektur ResNetSDE yang diusulkan mencapai skor F1 terkini di empat dari lima kumpulan data tolok ukur. Pada Fashion-MNIST, ResNetSDE memperoleh skor F1 sebesar 0,937 (CI: 0,932–0,941), mengungguli semua metode rekalibrasi dasar dengan margin 0,9%–1,3%. Untuk CIFAR-10 dan CIFAR-100, ResNetSDE masing-masing memperoleh 0,886 (CI: 0,879–0,892) dan 0,962 (CI: 0,958–0,965), melampaui ResNet-GE dan ResNet-CBAM masing-masing sebesar 3,5% dan 1,3%. ResNetSDE mendominasi SVHN dengan F1 sebesar 0,956 (CI: 0,953–0,958), peningkatan signifikan dibandingkan dengan ResNet-CBAM sebesar 0,948 (CI: 0,945–0,951). Sementara ResNet-CBAM unggul pada HAM10000 yang tidak seimbang kelasnya (0,770, CI: 0,758–0,782), ResNetSDE tetap kompetitif (0,768, CI: 0,749–0,786) karena keunggulannya yang konsisten—dibuktikan dengan interval kepercayaan yang sempit—memvalidasi kemanjurannya sebagai kerangka kerja kalibrasi ulang fitur.Percobaan kami menunjukkan bahwa SDERM dapat mengungguli modul kalibrasi ulang fitur yang ada dalam klasifikasi gambar. Integrasi SDERM ke ResNet memungkinkan pemanfaatan kemampuan beradaptasi terhadap stokastisitas setiap set data pada berbagai kedalaman arsitektur dalam klasifikasi gambar di mana ketidakpastian memainkan peran mendasar.
1 Pendahuluan
Arsitektur pembelajaran mendalam terus-menerus mendorong batasan kinerja di berbagai tugas visi komputer, termasuk klasifikasi gambar, deteksi objek, dan segmentasi semantik [ 1 – 4 ]. Namun, penerapan model-model ini memerlukan pertimbangan yang cermat, karena model-model ini hanya mewakili perkiraan dari distribusi dasar yang sebenarnya [ 5 – 7 ]. Kekhawatiran umum adalah ketergantungan pada lapisan keluaran softmax untuk memperoleh skor probabilitas, yang dapat menghasilkan prediksi yang terlalu percaya diri—terutama dalam skenario yang melibatkan kumpulan data yang tidak seimbang [ 8 – 10 ]. Masalah ini semakin diperburuk dalam aplikasi analisis gambar, seperti registrasi dan segmentasi gambar [ 3 , 4 ], di mana asumsi model deterministik sering kali menyebabkan kesalahan gabungan di serangkaian tugas [ 11 ]. Akumulasi kesalahan seperti itu menimbulkan tantangan signifikan terhadap keandalan analisis hilir, terutama dalam domain berisiko tinggi seperti pengambilan keputusan klinis [ 12 , 13 ]. Efektivitas model prediktif dalam konteks ini sering kali terganggu oleh dua sumber ketidakpastian utama: data masukan yang tidak akurat [ 9 , 10 ] dan asumsi pemodelan yang salah [ 13 ].
Mengatasi ketidakpastian ini sangat penting untuk mengembangkan sistem pembelajaran mesin yang andal dan tangguh. Dalam domain seperti perawatan kesehatan, di mana konsekuensi prediksi yang salah bisa sangat besar, mengelola ketidakpastian ini bukan hanya tujuan pengoptimalan tetapi juga persyaratan mendasar. Teknik kalibrasi ulang fitur dan strategi lain yang sadar akan ketidakpastian menjanjikan peningkatan keandalan model, khususnya dengan mengurangi rasa percaya diri yang berlebihan dan meningkatkan interpretabilitas prediksi dalam kumpulan data yang tidak seimbang dan kompleks [ 14 , 15 ].
Strategi rekalibrasi fitur konvensional dalam klasifikasi gambar, seperti normalisasi [ 16 ], adaptive pooling [ 17 , 18 ], dan pemangkasan fitur [ 19 , 20 ], bertujuan untuk meningkatkan kinerja model dengan menyempurnakan representasi fitur yang diekstraksi. Teknik normalisasi, seperti normalisasi batch dan normalisasi layer, menstabilkan pelatihan model dengan mengurangi pergeseran kovariat internal dan memastikan distribusi fitur yang konsisten [ 21 ]. Adaptive pooling secara dinamis menyesuaikan dimensi spasial untuk menangkap pola global dan lokal dalam data [ 22 ], sementara pemangkasan fitur memilih fitur yang paling informatif dengan menghapus yang tidak relevan berdasarkan perhitungan gradien [ 23 ], sehingga meningkatkan efisiensi dan mengurangi overfitting. Meskipun efisiensi komputasi dan penggunaannya luas, metode ini sering kali bergantung pada aturan tetap atau kriteria evaluasi yang dangkal, seperti besaran gradien, yang membatasi kemampuannya untuk beradaptasi dengan pola data yang kompleks dan rumit [ 21 , 24 , 25 ]. Akibatnya, kinerjanya mungkin kurang memuaskan pada tugas yang memerlukan presisi tinggi, pemahaman kontekstual mendalam, atau interaksi fitur bernuansa, yang menggarisbawahi perlunya strategi kalibrasi ulang yang adaptif dan sadar konteks.
Dengan munculnya transformer, integrasi mekanisme perhatian seperti jaringan Squeeze-and-Excitation (SE) [ 26 ], Convolution Block Attention Module (CBAM) [ 27 ], Pose Attention Module (PAM) [ 28 ], dan Gather-and-Excite (GE) [ 29 ] ke dalam jaringan saraf konvolusional (CNN) telah merevolusi kalibrasi ulang fitur. Mekanisme ini mengubah kalibrasi ulang menjadi proses dinamis yang mengoptimalkan prioritas fitur di berbagai dimensi, mengatasi keterbatasan strategi tradisional. Secara khusus, SE, CBAM, dan GE menyempurnakan hubungan antar saluran dengan secara selektif meningkatkan relevansi saluran fitur, sementara PAM berfokus pada wilayah spasial yang penting untuk kinerja tugas, meningkatkan lokalisasi dan pengenalan objek. Selain itu, GE menangkap kesadaran konteks dengan mengintegrasikan informasi kontekstual global dan lokal.
Meskipun ada kemajuan, mekanisme berbasis perhatian seperti SE, CBAM, PAM, dan GE menunjukkan keterbatasan yang nyata. Misalnya, SE dan CBAM bergantung pada proses deterministik dengan arsitektur tetap, yang membatasi kemampuan beradaptasi mereka terhadap lingkungan yang kompleks, bising, atau tidak pasti [ 27 , 28 , 30 ]. Mekanisme lain, seperti PAM dan CBAM, juga dapat menimbulkan overhead komputasi karena sifatnya yang iteratif, membuatnya kurang praktis untuk aplikasi berskala besar atau terbatas sumber daya [ 27 , 28 ]. Operasi statis SE dan GE, seperti pengumpulan yang telah ditentukan sebelumnya, juga menghambat kemampuan mereka untuk menangkap interaksi fitur yang berkembang secara dinamis, mengurangi efektivitas dalam menangani pola yang bervariasi secara temporal [ 26 , 29 ]. Lebih jauh lagi, CBAM dan PAM sering memperlakukan dimensi spasial dan saluran secara independen, yang mengarah ke kalibrasi ulang yang tidak optimal dalam skenario yang memerlukan dependensi lintas dimensi [ 17 ]. Selain itu, model seperti SE dan CBAM memperburuk masalah gradien yang menghilang dalam jaringan yang lebih dalam, sehingga membatasi kapasitasnya untuk kalibrasi ulang fitur-fitur halus secara mendetail [ 31 – 33 ]. Karena kekurangan ini, mekanisme berbasis perhatian yang ada tidak dapat melakukan kalibrasi ulang fitur yang sadar akan ketidakpastian, sehingga tidak dapat menangkap ketidakpastian yang melekat dalam data dan prediksi. Keterbatasan ini mengurangi keandalannya dalam aplikasi yang memerlukan pengambilan keputusan yang kuat dalam kondisi yang tidak pasti.
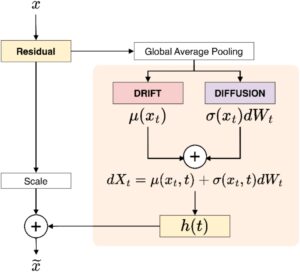
Untuk mengatasi tantangan ini, kami mengusulkan Modul Kalibrasi Ulang Persamaan Diferensial Stokastik (SDERM), pendekatan baru yang memperkenalkan stokastisitas ke dalam kalibrasi ulang fitur untuk memodelkan ketidakpastian secara eksplisit dengan mengambil inspirasi dari sistem dinamis dan proses stokastik. Pendekatan ini menggunakan metode Euler–Maruyama untuk memecahkan Persamaan Diferensial Stokastik (SDE), yang memungkinkan penyesuaian dinamis respons fitur berdasarkan saluran di CNN. SDE secara inheren memperhitungkan variabilitas dan keacakan dengan memodelkan interaksi fitur sebagai lintasan stokastik daripada pemetaan deterministik. Hal ini memungkinkan SDERM untuk menangkap ketidakpastian dalam distribusi data, pola fitur yang bising, dan variasi yang tidak dapat diprediksi selama inferensi model. Sifat stokastik dari proses kalibrasi ulang memungkinkan SDERM untuk secara adaptif memprioritaskan fitur dengan ketidakpastian tinggi sambil mengurangi kepercayaan diri yang berlebihan dalam prediksi. Lebih jauh lagi, kalibrasi ulang yang digerakkan SDE secara inheren mengintegrasikan dependensi kontekstual global dan lokal, meningkatkan ketahanan dalam tugas-tugas yang menuntut presisi tinggi dalam kondisi yang tidak pasti.
2 Pekerjaan Terkait
Strategi kalibrasi ulang telah terbukti berhasil dalam klasifikasi gambar yang meningkatkan representasi fitur dan kinerja model. SE memperkenalkan kalibrasi ulang berdasarkan saluran dengan memanfaatkan pengumpulan rata-rata global (GAP) dan mekanisme gating, sehingga memungkinkan model untuk menekankan fitur yang relevan secara efisien. Setelah ini, jaringan perhatian residual menggabungkan mekanisme perhatian dengan pembelajaran residual untuk menyempurnakan pemilihan fitur di seluruh kedalaman jaringan. CBAM memperluas konsep-konsep ini dengan menerapkan perhatian spasial dan berdasarkan saluran secara berurutan, sehingga memberikan kalibrasi ulang yang lebih bernuansa yang berfokus pada relevansi spasial dan saluran. Sementara itu, modul GE memperkenalkan pendekatan baru dengan menggabungkan informasi spasial untuk mengkalibrasi ulang fitur secara adaptif, yang menekankan pentingnya konteks spasial. Modul Kalibrasi Ulang Berbasis Gaya (SRM) mengkalibrasi ulang fitur berdasarkan pola gaya yang dipelajari, yang menyoroti pentingnya elemen gaya gambar [ 34 ]. Modul Rekalibrasi Sadar Posisi (PARM) meningkatkan representasi fitur dengan mempertimbangkan hubungan spasial, menggunakan kalibrasi khusus posisi [ 35 ], sementara Modul Pemisahan dan Kalibrasi Ulang Fitur (FSRM) membagi fitur ke dalam kelompok-kelompok berbeda sebelum kalibrasi ulang, yang memungkinkan peningkatan yang ditargetkan. Sementara strategi rekalibrasi efisien dalam meningkatkan representasi fitur melalui berbagai mekanisme, strategi ini terutama berfokus pada mengekstraksi informasi global atau menekankan aspek-aspek tertentu dari data, seperti hubungan spasial atau elemen gaya, sering kali dengan mengorbankan hilangnya detail yang lebih halus. Selain itu, mereka tidak mengatasi ketidakpastian yang melekat dalam data, seperti noise atau variabilitas di seluruh peta fitur. Kelalaian ini berarti bahwa sementara blok rekalibrasi ini dapat secara signifikan meningkatkan kinerja model dengan memprioritaskan fitur-fitur yang relevan, mereka mungkin tidak sepenuhnya menangkap kompleksitas dan variabilitas data dunia nyata, yang berpotensi membatasi kemampuan beradaptasi dan kekokohannya dalam lingkungan yang tidak pasti atau berisik.
3 SDERM



6 Percobaan
Kami melakukan eksperimen ekstensif pada lima set data gambar yang tersedia untuk umum guna mengevaluasi efektivitas mekanisme kalibrasi ulang fitur dalam klasifikasi gambar. Set data ini meliputi CIFAR-10 dan CIFAR-100, yang terdiri dari gambar beresolusi rendah (32 × 32 piksel) pada 10 dan 100 kelas, masing-masing distandarkan dengan 10.000 gambar uji; SVHN (Nomor Rumah Street View), set data pengenalan digit dunia nyata yang berasal dari gambar rambu jalan (32 × 32 piksel), dievaluasi pada set uji kanoniknya yang terdiri dari 26.032 gambar; Fashion-MNIST, set data skala abu-abu dari item pakaian berukuran 28 × 28 piksel yang mencakup 10 kelas, dengan pembagian uji yang telah ditetapkan sebanyak 10.000 gambar; dan HAM10000 (Human Against Machine dengan 10.000 gambar dermatoskopik), set data pencitraan medis beresolusi tinggi untuk klasifikasi lesi kulit pada tujuh kategori diagnostik, dengan 1511 gambar uji. Secara kolektif, himpunan data ini mencakup beragam domain (pemandangan alam, angka dunia nyata, produk konsumen, dan diagnostik medis), resolusi, dan tantangan klasifikasi, yang menawarkan landasan yang ketat dan beragam untuk menilai teknik kalibrasi ulang.
Tiga varian arsitektur ResNet—ResNet50, ResNet101, dan ResNet152—dimanfaatkan sebagai model utama untuk eksperimen kami. Setiap varian dievaluasi dengan enam mekanisme kalibrasi ulang fitur yang berbeda, menghasilkan 18 konfigurasi model. Model dasar adalah arsitektur ResNet asli, yang menggabungkan struktur kemacetan tanpa blok kalibrasi ulang tambahan. Untuk mengeksplorasi dampak kalibrasi ulang fitur, kami melengkapi model ResNet dengan lima modul kalibrasi ulang canggih: SE, GE, CBAM, PARM, dan SDERM yang kami usulkan. Modul-modul ini dipilih sebagai pembanding karena pendekatannya yang beragam terhadap penentuan prioritas fitur, termasuk kalibrasi ulang berdasarkan saluran (SE dan GE), perhatian spasial dan saluran (CBAM), dan penyesuaian adaptif spasial (PARM).
Semua model diimplementasikan dengan cermat dari awal menggunakan kerangka kerja PyTorch, memastikan konsistensi dan menghilangkan potensi bias yang disebabkan oleh bobot yang telah dilatih sebelumnya. Pilihan yang disengaja ini memberikan dasar yang seragam untuk mengevaluasi efektivitas setiap mekanisme kalibrasi ulang dalam klasifikasi gambar. Untuk menilai kinerja secara komprehensif, dua metrik utama digunakan: akurasi, untuk mengukur kebenaran prediksi secara keseluruhan, dan skor F1, untuk memperhitungkan keseimbangan antara presisi dan perolehan kembali, yang sangat penting dalam kumpulan data dengan ketidakseimbangan kelas seperti HAM10000. Kerangka kerja evaluasi yang ketat ini memungkinkan perbandingan menyeluruh atas kemampuan model dalam meningkatkan hasil klasifikasi di berbagai kumpulan data.
7 Hasil
Kinerja SDERM dievaluasi di lima set data klasifikasi gambar yang tersedia untuk umum—CIFAR-10, CIFAR-100, SVHN, Fashion-MNIST, dan HAM10000—menggunakan tiga arsitektur ResNet: ResNet50, ResNet101, dan ResNet152. Konfigurasi dasar ResNet (yang menggabungkan blok-blok hambatan) dibandingkan dengan lima mekanisme kalibrasi ulang fitur: SE, CBAM, GE, PAM, dan SDERM yang diusulkan. Evaluasi didasarkan pada akurasi 1% teratas, metrik standar untuk kinerja klasifikasi di berbagai set data.
SDERM secara konsisten mengungguli semua mekanisme kalibrasi ulang lainnya dan konfigurasi ResNet dasar di sebagian besar kumpulan data dan varian ResNet. Jika dibandingkan dengan struktur kemacetan dasar, SDERM mencapai peningkatan substansial. Pada CIFAR-10, ResNet152 + SDERM mencapai 88,92%, melampaui ResNet152 dengan blok kemacetan dengan margin 3,48%. Pada CIFAR-100, peningkatan kinerja bahkan lebih jelas, dengan ResNet152 + SDERM mencapai akurasi 97,92%, dibandingkan dengan 86,13% untuk dasar, yang mewakili peningkatan 11,79%. Demikian pula, pada SVHN, ResNet152 + SDERM mencapai 95,90%, secara signifikan mengungguli 94,25% dasar. Pada Fashion-MNIST, ResNet152 + SDERM mencapai 94,01%, peningkatan 1,93% dari nilai dasar. Terakhir, pada HAM10000, kumpulan data pencitraan medis yang menantang, SDERM menunjukkan sedikit peningkatan, mencapai akurasi 76,80% dibandingkan dengan nilai dasar ResNet152 sebesar 76,51%, yang menggarisbawahi kemampuan SDERM untuk menangani tugas klasifikasi khusus domain beresolusi tinggi secara efektif.
Jika dibandingkan dengan mekanisme kalibrasi ulang fitur lainnya, SDERM menunjukkan keunggulan yang konsisten di sebagian besar kumpulan data dan arsitektur. Pada CIFAR-10 dan CIFAR-100, SDERM mencapai akurasi tertinggi di semua mekanisme kalibrasi ulang, dengan ResNet152 + SDERM melampaui PAM (masing-masing 85,04% dan 91,35%) dan CBAM (masing-masing 84,83% dan 95,85%). Demikian pula, pada SVHN, SDERM dengan ResNet152 mencapai 95,90%, mengungguli PAM (94,86%) dan CBAM (94,48%). Pada Fashion-MNIST, SDERM mencapai akurasi tertinggi (94,01%), sedikit melampaui PAM (93,01%). Namun, ada beberapa contoh di mana mekanisme kalibrasi ulang lainnya sedikit mengungguli SDERM. Misalnya, pada kumpulan data HAM10000, CBAM mencapai akurasi tertinggi (78,44%) dengan ResNet152, mengungguli SDERM (76,80%) sebesar 1,64%. Demikian pula, PAM menunjukkan kinerja yang sebanding pada Fashion-MNIST dan HAM10000, masing-masing mencapai 93,01% dan 76,49% pada ResNet152.
Tren penting juga diamati di mana kinerja SDERM berskala positif dengan arsitektur ResNet yang lebih dalam, dengan ResNet152 secara konsisten mengungguli ResNet101 dan ResNet50 di semua set data. Tren ini menunjukkan bahwa SDERM secara efektif memanfaatkan peningkatan kapasitas representasional dari model yang lebih dalam, yang selanjutnya meningkatkan kemampuan kalibrasi ulangnya. Sebaliknya, sementara CBAM dan PAM kadang-kadang mencapai hasil yang kompetitif, kinerjanya tidak berskala secara konsisten seperti SDERM di seluruh set data dan arsitektur. Temuan ini menyoroti kemampuan SDERM untuk mengkalibrasi ulang fitur secara dinamis dan mengurangi keterbatasan kemacetan dalam arsitektur yang lebih dalam. Lebih jauh, SDERM menunjukkan ketahanan di seluruh domain dengan kompleksitas yang bervariasi. Misalnya, ia mencapai hasil mutakhir pada set data dengan gambar beresolusi rendah, seperti CIFAR-10 dan CIFAR-100, serta pada set data khusus domain beresolusi tinggi seperti HAM10000, yang penting untuk aplikasi medis. Pada HAM10000, meskipun CBAM mencapai akurasi tertinggi, kemampuan SDERM untuk memodelkan dan memprioritaskan fitur yang tidak pasti terbukti menguntungkan, menggarisbawahi potensinya untuk meningkatkan klasifikasi dalam aplikasi berisiko tinggi seperti perawatan kesehatan. Selain itu, kemampuan SDERM untuk mengurangi rasa percaya diri yang berlebihan dan mengkalibrasi ulang fitur secara dinamis sangat bermanfaat dalam kumpulan data dengan ketidakseimbangan kelas, seperti HAM10000, di mana kelas tertentu kurang terwakili secara signifikan.
Untuk mengevaluasi kemanjuran strategi kalibrasi ulang fitur, kami menghitung skor F1 di lima set data tolok ukur dengan merata-ratakan kinerja di tiga arsitektur ResNet (ResNet50, ResNet101, ResNet152) dengan interval kepercayaan 95% yang berasal dari galat baku rata-rata di seluruh arsitektur. Seperti yang ditunjukkan dalam Tabel 1 , SDERM menunjukkan kinerja mutakhir pada CIFAR-100, SVHN, dan FashionMNIST, dengan mencapai skor F1 masing-masing sebesar 0,962 (0,958–0,965), 0,956 (0,953–0,958), dan 0,937 (0,932–0,941). Khususnya, pada CIFAR-100, SDERM melampaui metode terbaik berikutnya, CBAM (0,949 [0,945–0,953]), dengan margin yang signifikan secara statistik ( p < 0,01, uji t berpasangan di seluruh arsitektur). Namun, metode berbasis perhatian spasial menunjukkan keunggulan khusus kumpulan data: PAM mencapai kinerja CIFAR-10 tertinggi (0,942 [0,938–0,945]), kemungkinan karena kapasitasnya untuk memprioritaskan daerah diskriminatif dalam gambar alami, sementara CBAM memimpin pada kumpulan data HAM10000 yang tidak seimbang kelas (0,770 [0,758–0,782]), sedikit mengungguli SDERM (0,768 [0,749–0,786]). Metode kalibrasi ulang per saluran tradisional juga menunjukkan kekuatan khusus, dengan SE unggul pada CIFAR-100 (0,951 [0,947–0,955]) dan GE pada FashionMNIST (0,928 [0,923–0,932]). Dominasi SDERM yang konsisten di tiga tolok ukur, ditambah dengan interval kepercayaannya yang sempit (maks Δ = 0,013), menggarisbawahi kekokohan arsitekturnya dan penerapannya yang lebih luas dibandingkan dengan pendekatan khusus tugas.
| Kalibrasi ulang fitur | 1% teratas acc | ||||
|---|---|---|---|---|---|
| CIFAR10 = 10.000 | CIFAR100 = 10.000 | Nomor SVHN = 26.032 | FashionMNIST n = 10.000 | HAM n = 1511 | |
| Kemacetan | 0,854 (0,851, 0,858) | 0,833 (0,828, 0,837) | 0,939 (0,935, 0,942) | 0,926 (0,921, 0,930) | 0,753 (0,741, 0,765) |
| Bahasa Inggris | 0,848 (0,844, 0,852) | 0,951 (0,947, 0,955) | 0,942 (0,938, 0,946) | 0,925 (0,921, 0,930) | 0,766 (0,754, 0,778) |
| Bahasa Inggris CBAM | 0,831 (0,827, 0,836) | 0,949 (0,945, 0,953) | 0,948 (0,945, 0,951) | 0,926 (0,921, 0,931) | 0,770 (0,758, 0,782) |
| PAM | 0,942 (0,938, 0,945) | 0,905 (0,900, 0,910) | 0,942 (0,938, 0,945) | 0,924 (0,920, 0,928) | 0,766 (0,754, 0,779) |
| GE | 0,851 (0,847, 0,855) | 0,891 (0,886, 0,897) | 0,941 (0,938, 0,944) | 0,928 (0,923, 0,932) | 0,770 (0,758, 0,782) |
| SDERM | 0,886 (0,879, 0,892) | 0,962 (0,958, 0,965) | 0,956 (0,953, 0,958) | 0,937 (0,932, 0,941) | 0,768 (0,749, 0,786) |
Singkatnya, SDERM secara konsisten mencapai akurasi yang unggul di sebagian besar kumpulan data dan konfigurasi model, mengungguli baseline kemacetan dan mekanisme kalibrasi ulang canggih lainnya dalam sebagian besar kasus. Kemampuannya untuk memanfaatkan dinamika stokastik untuk kalibrasi ulang yang sadar ketidakpastian berperan penting dalam meningkatkan kinerja klasifikasi, khususnya dalam kumpulan data yang menantang dengan variabilitas tinggi, ketidakseimbangan, atau kompleksitas khusus domain. Meskipun demikian, kinerja CBAM dan PAM yang unggul sesekali menyoroti pentingnya strategi kalibrasi ulang khusus tugas. Hasil ini memposisikan SDERM sebagai modul kalibrasi ulang yang tangguh dan dapat diskalakan yang cocok untuk berbagai tugas klasifikasi gambar, sambil mengakui area di mana pendekatan alternatif dapat menawarkan keuntungan marjinal.
8 Model Penjelasan
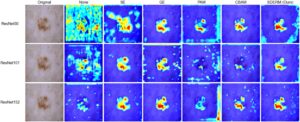
Kami mengevaluasi hasil prediksi pada GradCAM untuk memberikan wawasan penting mengenai efektivitas berbagai mekanisme kalibrasi ulang fitur menggunakan set data uji HAM10000 untuk keterjelasan model. Hasil menunjukkan perbedaan signifikan dalam cara masing-masing model mengidentifikasi fitur penting dalam gambar lesi kulit.
Seperti yang ditunjukkan pada Gambar 2 , ResNet dasar menunjukkan perhatian yang tersebar dan tidak konsisten, dengan area lesi utama kurang ditekankan atau terlewatkan sama sekali, seperti yang ditunjukkan oleh dominasi daerah kuning di ResNet50 dan ResNet101 sementara prediksi yang jarang pada ResNet152. Kurangnya fokus pada fitur yang relevan secara diagnostik ini mencerminkan kemampuan dasar yang terbatas untuk melokalisasi daerah kritis secara akurat, yang berkontribusi pada kinerja klasifikasi yang lebih rendah (Tabel 2 ). Sebaliknya, modul SE dan GE memberikan peningkatan sedang, karena peta panasnya menunjukkan lebih banyak perhatian (daerah kuning dan kadang-kadang merah) yang terkonsentrasi di dekat area lesi. Namun, fokusnya tetap menyebar, dan batas lesi kritis tidak ditekankan secara konsisten, yang membatasi kemampuannya untuk memprioritaskan fitur utama secara efektif. GE menghasilkan lebih sedikit noise dan berfokus pada daerah sedang hingga penting (kuning dan merah) tetapi tidak memiliki presisi berbutir halus yang terlihat di SDERM. Sementara itu, PAM menunjukkan gangguan yang berlebihan (ResNet101-PAM) karena peta panasnya menunjukkan perhatian yang tersebar dan menyebar di seluruh wilayah yang relevan dan tidak relevan. Meskipun PAM menyoroti wilayah lesi dengan area kuning dan merah, fokus yang lebih luas ini sering meluas ke area yang tidak relevan, seperti batas latar belakang (ResNet152-PAM), sehingga mengurangi kemampuannya untuk secara konsisten memprioritaskan fitur-fitur penting. CBAM meningkat secara signifikan dibandingkan PAM dengan menunjukkan perhatian yang lebih terlokalisasi pada batas lesi (ResNet50, ResNet152 untuk CBAM), tetapi peta panasnya masih mencakup area kuning yang tersebar di luar wilayah yang relevan secara diagnostik di ResNet101. SE menunjukkan lebih sedikit gangguan dalam prediksinya daripada CBAM dan PAM, dengan peta panas yang secara konsisten menyoroti wilayah lesi yang relevan tanpa perhatian yang berlebihan pada area yang tidak relevan.
| Model | Kalibrasi ulang fitur | 1% teratas acc | ||||
|---|---|---|---|---|---|---|
| CIFAR10 = 10.000 (%) | CIFAR100 = 10.000 (%) | Nomor SVHN = 26.032 (%) | FashionMNIST n = 10.000 (%) | HAM = 1511 (%) | ||
| ResNet50 | Kemacetan | 84.00 | 83.46 | 93.86 | 92.55 | pukul 75.30 |
| ResNet101 | Kemacetan | 83.72 | 84.32 | 93.87 | 92.58 | 74.38 |
| ResNet152 | Kemacetan | 85.44 | 86.13 | 94.25 | 92.08 | 76.51 |
| ResNet50 | Bahasa Inggris | 84.77 | 95.09 | 94.18 | 92.53 | 76.61 |
| ResNet101 | Bahasa Inggris | 82.54 | 93.86 | 94.76 | 92.54 | 76.5 |
| ResNet152 | Bahasa Inggris | 85.07 | 94.73 | 94.35 | 92.68 | 74.69 |
| ResNet50 | Bahasa Inggris CBAM | 83.14 | 94.88 | 94.80 | 92.58 | Rp 77.000 |
| ResNet101 | Bahasa Inggris CBAM | 82.72 | 91.06 | 94.46 | 92.29 | 76.32 |
| ResNet152 | Bahasa Inggris CBAM | 84.83 | 95.85 | 94.48 | 92.96 | 78.44 |
| ResNet50 | PAM | 94.15 | 90.49 | 94.15 | 92.41 | 76.64 |
| ResNet101 | PAM | 94.37 | 91.16 | 94.37 | 92.38 | 75.29 |
| ResNet152 | PAM | 85.04 | 91.35 | 94.86 | 93.01 | 76.49 |
| ResNet50 | GE | 85.10 | 89.13 | 94.12 | 92.75 | 77.02 |
| ResNet101 | GE | 85.92 | 89.42 | Nomor 94.11 | 92.44 | 75.17 |
| ResNet152 | GE | 84.38 | 90.32 | 94.14 | 92.88 | 77.22 |
| ResNet50 | SDERM (Milik Kami) | 87.95 | 96.16 | 95.23 | 94.07 | 76.73 |
| ResNet101 | SDERM (Milik Kami) | 88.06 | 97.32 | 95.59 | 92.98 | 76.07 |
| ResNet152 | SDERM (Milik Kami) | 88.92 | 97.92 | 95.90 | 94.01 | 76.80 |
Catatan: Angka tebal menunjukkan nilai akurasi 1% tertinggi.
Kami juga mengevaluasi gambar uji yang pudar dan rumit dari dataset HAM10000, seperti yang ditunjukkan pada Gambar 3. Kebenaran dasar menampilkan lesi samar dengan visibilitas rendah, yang menantang kemampuan model untuk melokalisasi fitur-fitur utama. Modul SE cukup menyorot daerah yang relevan (area kuning) tetapi kurang presisi, gagal mengisolasi lesi secara akurat. PAM memperkenalkan noise yang berlebihan, dengan daerah merah dan kuning yang tersebar meluas ke area yang tidak relevan, yang menunjukkan keterbatasannya dalam skenario kontras rendah. Sebaliknya, SDERM menunjukkan fokus yang paling tepat, dengan daerah merah yang sangat selaras dengan lesi samar dan noise minimal di latar belakang (area biru). Ini menyoroti kemampuan SDERM untuk mengkalibrasi ulang fitur secara adaptif, menangani ketidakpastian secara efektif, dan memberikan hasil yang andal untuk lesi yang halus dan kontras rendah, menjadikannya pendekatan yang paling kuat dalam kasus-kasus yang menantang tersebut.

Gambar 4 mengilustrasikan keefektifan SDERM dalam melokalisasi fitur-fitur relevan di seluruh gambar uji kontras rendah dari CIFAR-10, CIFAR-100, FashionMNIST, dan SVHN menggunakan GradCAM. Dalam CIFAR-10 dan CIFAR-100, SDERM secara akurat menyorot area-area utama yang masing-masing sesuai dengan kelas kuda dan burung, mengungguli baseline, GE, dan CBAM, yang memperlihatkan perhatian yang tersebar atau salah tempat. Sementara SE dan PAM menghasilkan hasil yang sebanding, keduanya masih mengalami noise yang nyata (misalnya, PAM dalam CIFAR-10 dan SE dalam CIFAR-100), yang menyebabkan kebocoran perhatian ke area-area yang tidak relevan. Dalam FashionMNIST, SDERM secara tajam berfokus pada kemeja lengan panjang, sedangkan model baseline gagal melokalisasi objek. SE dan PAM menawarkan peningkatan sedang, tetapi GE dan CBAM menimbulkan noise latar belakang meskipun menangkap area kemeja. Pada SVHN, SDERM melokalisasi digit “1” dengan gangguan minimal terhadap digit “210” pada gambar asli. Sebaliknya, metode kalibrasi ulang lainnya kesulitan untuk mengisolasi digit secara konsisten, sering kali salah mengalokasikan fokus atau mengaburkan batasan yang relevan dengan kelas.

9 Diskusi
SDERM secara konsisten mencapai akurasi yang lebih tinggi daripada struktur bottleneck dasar dan mekanisme rekalibrasi fitur lainnya, termasuk SE, CBAM, GE, dan PAM, karena SDE, yang memodelkan dinamika deterministik dan stokastik. Dengan secara eksplisit memodelkan ketidakpastian melalui istilah difusi, SDERM secara efektif memprioritaskan fitur yang andal sambil menurunkan bobot ketidakpastian atau representasi fitur yang bising. Pendekatan ini memungkinkan SDERM untuk menggeneralisasi dengan baik di seluruh distribusi data yang bervariasi, selaras dengan penelitian sebelumnya yang menekankan peran pemodelan stokastik dalam meningkatkan ketahanan dan generalisasi dalam model pembelajaran mesin [ 36 – 38 ]. Selain itu, kombinasi koneksi residual dan penskalaan perkalian dalam SDERM menjaga integritas fitur input sambil secara dinamis meningkatkan pentingnya fitur, sebuah mekanisme yang telah terbukti meningkatkan aliran gradien dan mencegah hilangnya informasi dalam jaringan dalam [ 39 , 40 ]. Kehilangan rekalibrasi, yang menyelaraskan fitur yang dikalibrasi ulang dengan konfigurasi fitur yang paling mungkin, selanjutnya memastikan bahwa SDERM secara konsisten mengungguli pendekatan yang murni deterministik, seperti SE dan CBAM, yang bergantung pada pola perhatian tetap.
Kinerja SDERM diskalakan secara positif dengan kedalaman arsitektur ResNet, dengan ResNet152 secara konsisten mencapai akurasi tertinggi di semua set data. Tren ini menggarisbawahi kemampuan SDERM untuk secara efektif memanfaatkan peningkatan kapasitas representasional dari model yang lebih dalam. Jaringan yang lebih dalam secara inheren mempelajari representasi hierarkis yang lebih kaya, membuatnya lebih rentan terhadap overfitting atau ketidakstabilan, terutama dalam tugas yang melibatkan variabilitas atau ketidakpastian yang tinggi [ 41 – 43 ]. Namun, rekalibrasi stokastik SDERM mengurangi masalah ini dengan mengatur proses pembelajaran fitur dan secara adaptif mengkalibrasi ulang pentingnya fitur berdasarkan keandalannya. Penskalaan positif SDERM dengan kedalaman model juga menyoroti pentingnya koneksi residual dalam modul. Koneksi ini memastikan bahwa penyesuaian stokastik SDERM tidak mengganggu aliran informasi dalam jaringan yang lebih dalam, suatu mekanisme yang telah didokumentasikan dengan baik dalam kerangka kerja pembelajaran residual seperti ResNet dan DenseNet [ 44 , 45 ]. Properti ini khususnya menguntungkan dalam himpunan data dengan fitur berbutir halus atau keragaman kelas tinggi, seperti CIFAR-100, di mana SDERM mencapai peningkatan substansial atas struktur kemacetan dasar dan mekanisme rekalibrasi yang bersaing.
Sementara SDERM menunjukkan kinerja yang unggul dalam kebanyakan kasus, ada contoh di mana mekanisme rekalibrasi lainnya, khususnya CBAM dan PAM, mencapai akurasi yang lebih tinggi. Misalnya, CBAM mencapai akurasi tertinggi pada dataset HAM10000. Hal ini dapat dikaitkan dengan penggunaan eksplisit CBAM atas perhatian spasial dan saluran, yang dapat memberikan keuntungan dalam dataset yang memerlukan lokalisasi yang tepat dari fitur-fitur penting secara spasial, seperti gambar medis [ 27 , 31 , 32 ]. Demikian pula, kinerja kompetitif PAM dalam skenario tertentu, seperti Fashion-MNIST, dapat dijelaskan oleh kemampuannya untuk menangkap dependensi khusus posisi [ 28 ], yang sangat penting dalam dataset dengan kelas yang terstruktur secara visual. Kinerja SDERM yang sedikit lebih rendah dalam kasus-kasus ini menunjukkan bahwa ketergantungannya pada pemodelan stokastik dapat menyebabkan rekalibrasi fitur yang kurang optimal dalam skenario di mana distribusi data relatif deterministik [ 46 ], atau di mana mekanisme perhatian spasial atau posisi tertentu lebih efektif. Hal ini sejalan dengan temuan sebelumnya bahwa pendekatan stokastik, meskipun secara umum kuat, mungkin berkinerja buruk dalam tugas yang didominasi oleh pola yang tetap atau dapat diprediksi [ 36 , 38 , 46 , 47 ].
Salah satu kekuatan SDERM yang paling signifikan adalah ketahanannya terhadap kumpulan data dengan berbagai karakteristik, termasuk kumpulan data beresolusi rendah (CIFAR-10 dan CIFAR-100), data dunia nyata skala besar (SVHN), dan kumpulan data khusus domain beresolusi tinggi (HAM10000). Kemampuan beradaptasi ini dapat dikaitkan dengan kemampuan SDERM untuk mengkalibrasi ulang fitur secara dinamis berdasarkan dependensi global dan lokal, serta mekanisme difusi stokastiknya, yang memungkinkannya memperhitungkan ketidakpastian dalam distribusi data yang beragam. Pada kumpulan data beresolusi rendah seperti CIFAR-10 dan CIFAR-100, efektivitas SDERM berasal dari kemampuannya untuk memprioritaskan fitur yang paling diskriminatif dalam skenario di mana detail yang sangat rinci terbatas. Dalam kumpulan data berskala besar seperti SVHN, dinamika stokastik SDERM membantu mengurangi kebisingan dan variabilitas yang melekat pada data dunia nyata [ 48 ], sejalan dengan temuan bahwa prioritas fitur stokastik meningkatkan ketahanan dalam lingkungan yang bising. Terakhir, pada kumpulan data beresolusi tinggi seperti HAM10000, proses kalibrasi ulang SDERM secara efektif menyeimbangkan ketergantungan fitur global dan lokal, yang sangat penting dalam tugas pencitraan medis di mana pola halus dan informasi kontekstual sama pentingnya.
Hasilnya menunjukkan keunggulan SDERM yang konsisten atas mekanisme kalibrasi ulang dasar dan yang bersaing dalam sebagian besar skenario, skalabilitasnya dengan arsitektur yang lebih dalam, dan kekokohannya di berbagai kumpulan data. Sementara mekanisme alternatif terkadang mengungguli SDERM dalam tugas-tugas tertentu, kinerja keseluruhannya menyoroti keuntungan dari menggabungkan dinamika deterministik dan stokastik untuk kalibrasi ulang fitur. Temuan ini menggarisbawahi potensi SDERM untuk memajukan klasifikasi gambar, khususnya dalam aplikasi dengan ketidakpastian tinggi dan khusus domain seperti perawatan kesehatan.
10. Kesimpulan
Studi ini memperkenalkan SDERM dan mengevaluasi kinerjanya di berbagai tugas klasifikasi gambar. Hasilnya menunjukkan bahwa SDERM secara konsisten mengungguli struktur kemacetan dasar dan mekanisme kalibrasi ulang fitur yang bersaing, khususnya pada kumpulan data yang menantang seperti CIFAR-100 dan SVHN, di mana variabilitas dan ketidakpastian lazim terjadi. Integrasi dinamika stokastik SDERM melalui SDE memungkinkan kalibrasi ulang fitur yang sadar ketidakpastian, memberikan ketahanan di seluruh kumpulan data dengan berbagai karakteristik. Kemampuannya untuk diskalakan dengan arsitektur ResNet yang lebih dalam semakin menggarisbawahi efektivitasnya dalam memanfaatkan peningkatan kapasitas model untuk penentuan prioritas fitur yang lebih akurat. Sementara mekanisme alternatif, seperti CBAM dan PAM, terkadang mencapai hasil yang lebih baik dalam skenario tertentu, kinerja SDERM secara keseluruhan menyoroti kemampuan beradaptasi dan keandalannya. Temuan ini menetapkan SDERM sebagai mekanisme kalibrasi ulang fitur yang tangguh dan dapat diskalakan, dengan potensi signifikan untuk memajukan klasifikasi gambar secara umum dan aplikasi khusus domain seperti pencitraan medis. Pekerjaan di masa mendatang dapat mengeksplorasi pengoptimalan SDERM lebih lanjut untuk menangani tugas yang memerlukan mekanisme perhatian spasial atau posisional khusus.