ABSTRAK
Perkenalan
Sintesis bukti sangat penting dalam perawatan kesehatan dan di tempat lain, tetapi membutuhkan banyak sumber daya, dan sering kali memerlukan waktu bertahun-tahun untuk diproduksi. Alat kecerdasan buatan dan pembelajaran mesin (AI/ML) dapat meningkatkan efisiensi produksi dalam fase peninjauan tertentu, tetapi sedikit yang diketahui tentang dampaknya terhadap keseluruhan peninjauan.
Metode
Kami melakukan analisis praspesifikasi dari sampel praktis tinjauan terkait perawatan kesehatan atau kesejahteraan yang memenuhi syarat yang ditugaskan di Institut Kesehatan Masyarakat Norwegia antara 1 Agustus 2020 (komisi pertama yang menggunakan AI/ML) dan 31 Januari 2023 (batas administratif). Paparan utama adalah penggunaan AI/ML mengikuti rekomendasi tim dukungan internal versus tidak ada penggunaan. Alat pemeringkatan (misalnya, penyaringan prioritas), klasifikasi (misalnya, desain studi), pengelompokan (misalnya, dokumen), dan analisis bibliometrik (misalnya, OpenAlex) disertakan, tetapi kami tidak menyertakan atau mengecualikan alat tertentu. Alat AI generatif tidak tersedia secara luas selama periode studi. Hasilnya adalah sumber daya (jam kerja) dan waktu dari komisi hingga penyelesaian (persetujuan untuk pengiriman, termasuk tinjauan sejawat; minggu). Analisis memperhitungkan penugasan non-acak dan hasil tersensor (tinjauan sedang berlangsung pada batas). Peneliti yang mengklasifikasikan paparan dibutakan terhadap hasil. Ahli statistik dibutakan terhadap paparan.
Hasil
Di antara 39 tinjauan, 7 (18%) merupakan penilaian teknologi kesehatan versus tinjauan sistematis, 19 (49%) berfokus pada perawatan kesehatan versus kesejahteraan, 18 (46%) merupakan meta-analisis terencana, dan 3 (8%) sedang berlangsung pada batas akhir. Alat AI/ML digunakan dalam 27 (69%) tinjauan. Tinjauan yang menggunakan AI/ML seperti yang direkomendasikan menggunakan lebih banyak sumber daya (rata-rata 667 vs. 291 jam kerja) tetapi diselesaikan sedikit lebih cepat (27,6 vs. 28,2 minggu). Perbedaan ini tidak signifikan secara statistik (penggunaan sumber daya relatif 3,71; 95% CI: 0,36–37,95; p = 0,269; waktu penyelesaian relatif: 0,92; 95% CI: 0,53–1,58; p = 0,753).
Kesimpulan
Hubungan antara penggunaan AI/ML dan hasilnya masih belum pasti. Studi multisenter atau meta-analisis mungkin diperlukan untuk menentukan apakah alat ini secara signifikan mengurangi penggunaan sumber daya dan waktu untuk menghasilkan sintesis bukti.
1 Pendahuluan
Sintesis bukti seperti tinjauan sistematis dan penilaian teknologi kesehatan (selanjutnya disebut ‘tinjauan’) sangat berdampak pada perawatan kesehatan, kesejahteraan, dan area lainnya, tetapi produksi membutuhkan banyak sumber daya dan dapat memakan waktu bertahun-tahun. Meskipun waktu dari memulai hingga menyelesaikan tinjauan kesehatan sangat bervariasi [ 1 ], lima belas bulan adalah waktu yang umum [ 2 , 3 ]. Cochrane menyarankan peninjau harus siap menghabiskan satu hingga dua tahun untuk melakukan tinjauan, tetapi hanya setengahnya yang diselesaikan dalam waktu 2 tahun sejak publikasi protokol dan waktu rata-rata untuk publikasi telah meningkat [ 4 ]. Banyak tinjauan—terutama yang diterbitkan oleh Cochrane dan penilaian teknologi kesehatan di bidang yang berkembang pesat seperti pengobatan kanker—perlu diperbarui untuk menyertakan bukti baru [ 5 ], sehingga penggunaan sumber daya sering kali melampaui publikasi pertama. Sekitar 25 persen tinjauan menjadi usang dalam waktu 2 tahun sejak publikasi [ 6 ].
1.1 Alat Kecerdasan Buatan dan Pembelajaran Mesin untuk Sintesis Bukti
Alat kecerdasan buatan dan pembelajaran mesin (AI/ML) dapat mengurangi kebutuhan manusia untuk melakukan tugas-tugas yang berulang dan kompleks. “Berulang dan kompleks” menggambarkan beberapa fase sintesis bukti, seperti penyaringan judul dan abstrak terhadap kriteria inklusi, mengekstraksi data, dan menilai risiko bias. Beberapa tugas, seperti menyaring uji coba, harus dilakukan ribuan kali untuk setiap tinjauan, seringkali oleh peneliti berpengalaman yang berpendidikan tinggi. Alat AI/ML telah digunakan untuk menyaring secara otomatis [ 7 – 9 ] dan mengklasifikasikan artikel [ 10 ], membantu menghasilkan tinjauan hidup [ 11 , 12 ], dan secara sistematis memetakan penelitian global tentang iklim dan kesehatan [ 13 ]. AI/ML menawarkan potensi untuk mengurangi penggunaan sumber daya, menghasilkan tinjauan dalam waktu yang lebih singkat, membantu pengulas baru dan yang tidak berpengalaman belajar [ 14 ], dan mempertahankan atau mungkin melampaui harapan saat ini tentang transparansi, reproduktifitas, dan ketelitian metodologis.
Alat AI/ML telah tersedia untuk peninjau sistematis setidaknya selama lima belas tahun [ 15 ]. Ada peningkatan bukti yang menunjukkan bahwa sumber daya yang substansial dapat dihemat pada fase peninjauan tertentu jika alat AI/ML diadopsi untuk membantu produksi [ 16 ]. Tinjauan tahun 2015 menemukan penghematan waktu sebesar 40%–70% dalam fase penyaringan saat menggunakan perangkat lunak penambangan teks [ 17 ]; kami melaporkan penghematan waktu yang serupa atau mungkin lebih (60%–90%) pada tahun 2021 [ 18 ]. Klasifikasi otomatis dan pengecualian desain non-acak dengan pengklasifikasi desain studi menghemat Cochrane Crowd dari penyaringan manual lebih dari 40% referensi yang diidentifikasi pada tahun 2018 [ 19 ]. Kami juga telah melaporkan bahwa mengkategorikan studi menggunakan pengelompokan otomatis menggunakan 33% dari waktu dibandingkan dengan kategorisasi manual [ 18 ].
Meskipun demikian, bidang sintesis bukti lambat dalam mengadopsi AI/ML [ 20 ], meskipun pandemi COVID-19 tampaknya telah meningkatkan penggunaan alat AI/ML dalam sintesis bukti [ 21 ]. Salah satu penjelasan untuk kurangnya pemanfaatan mungkin karena bidang tersebut telah berkembang dengan menyamakan upaya manusia dengan kualitas metodologis, sehingga otomatisasi dapat dilihat sebagai pengorbanan kualitas [ 22 ]. Penjelasan lain mungkin karena terlalu sedikit yang diketahui tentang apakah penghematan spesifik fase diterjemahkan menjadi penghematan sumber daya dan waktu untuk seluruh tinjauan.
1.2 Mengevaluasi Penggunaan Sumber Daya dan Waktu Penyelesaian
Studi saat ini memiliki tiga tujuan: untuk menilai apakah penggunaan AI/ML mengurangi penggunaan sumber daya dan waktu dari komisi peninjauan hingga penyelesaian; untuk memberikan informasi untuk membuat keputusan organisasi tingkat tinggi tentang AI/ML; dan membantu mendukung studi multisenter berikutnya, yang kami perkirakan akan diperlukan. Untuk alasan terakhir, kami menetapkan studi ini sebagai percontohan.
Mempelajari sumber daya yang digunakan untuk menghasilkan tinjauan menyeluruh penting karena produksi itu mahal. Mempelajari waktu penyelesaian penting karena jawaban atas pertanyaan penelitian yang terlambat tidak berguna. Oleh karena itu, mungkin lebih penting untuk mempelajari kedua hasil ini daripada penghematan dalam fase tinjauan individual, yang mungkin pada akhirnya tidak penting. Mengetahui apakah dan sejauh mana alat AI/ML mengurangi penggunaan sumber daya dan waktu penyelesaian dapat membantu produsen tinjauan memutuskan apakah akan mengadopsi alat tersebut, menganggarkan dan memberi harga pada produk dan layanan mereka, dan memahami bagaimana jadwal proyek dapat terpengaruh. A priori, berdasarkan penelitian yang tersedia yang cenderung berfokus pada fase tinjauan tertentu dan pengalaman kami sendiri, serta tujuan eksplisit alat AI/ML, kami akan berhipotesis (yaitu, mengharapkan) bahwa alat tersebut akan mengurangi penggunaan sumber daya dan waktu penyelesaian.
Kami mengetahui satu studi yang menilai waktu penyelesaian (beberapa hari dari prapendaftaran hingga pracetak atau penyerahan jurnal) serta beberapa hasil lain termasuk proksi untuk penggunaan sumber daya [ 23 ]. Penulis menemukan hubungan antara penggunaan AI/ML dan publikasi di jurnal dengan faktor dampak yang lebih tinggi, lebih banyak abstrak yang disaring per penulis dan studi yang disertakan, dan lebih sedikit teks lengkap yang diperiksa per penulis, tetapi tidak ada perbedaan untuk waktu penyelesaian. Namun, studi ini tidak mencoba memperhitungkan penugasan endogen (yaitu, tinjauan tidak diacak untuk menggunakan atau tidak menggunakan AI/ML), sehingga temuannya mungkin dapat membingungkan.
2 Metode
2.1 Pengaturan
Kami melakukan studi penelitian efektivitas komparatif menggunakan data retrospektif sebagaimana ditetapkan sebelumnya dalam protokol yang diterbitkan dan ditinjau sejawat [ 24 ]. Kelompok untuk Ulasan dan Penilaian Teknologi Kesehatan di Institut Kesehatan Masyarakat Norwegia (NIPH) mulai mengadopsi AI/ML pada tahun 2020 untuk membantu memetakan dan memproses sejumlah besar bukti COVID-19. Penggunaan AI/ML telah meningkat dari tidak ada penggunaan sebelum pandemi, menjadi 26 ulasan setelah tahun pertama, dan hampir semuanya sekarang [ 18 ]. Tim pendukung khusus didanai sejak akhir tahun 2020 dan ditugaskan untuk mengidentifikasi, mengevaluasi (seperti dalam artikel ini), dan menerapkan alat AI/ML secara berkelanjutan untuk membantu produksi ulasan, dan menyesuaikannya dengan prosedur dan proses kelembagaan [ 18 , 25 ]. Standar NIPH saat ini mengharuskan penggunaan AI/ML, kecuali dalam keadaan langka yang membenarkan penyimpangan pragmatis. Karena sebagian besar ulasan ditugaskan secara eksternal, informasi penggunaan sumber daya terperinci tersedia, yang kami analisis dalam studi ini untuk memperkirakan hubungan antara penggunaan AI/ML dan penggunaan sumber daya serta waktu penyelesaian.
2.2 Pengumpulan dan Ekstraksi Data
Kami memperoleh sampel praktis dari semua tinjauan yang dapat dianalisis mengenai topik perawatan kesehatan atau kesejahteraan yang ditugaskan di lembaga tersebut antara 1 Agustus 2020 (komisi pertama yang menggunakan AI/ML) dan 31 Januari 2023 (batas administratif). Tinjauan tidak akan dapat dianalisis jika kami tidak memiliki informasi yang diperlukan untuk menentukan salah satu variabel yang diperlukan. RCB mengirimkan daftar semua proyek yang berpotensi memenuhi syarat kepada seluruh tim dan, secara terpisah, mengekstrak data hasil, memastikan bahwa seluruh tim tidak mengetahui hasil tersebut. Peninjau sistematis JFME mengekstrak data pada variabel berikut untuk mendukung analisis statistik:
- Jenis sintesis yang direncanakan (tidak ada, seperti dalam tinjauan cakupan; meta-analisis berpasangan atau sintesis kualitatif; atau meta-analisis jaringan).
- Jenis tinjauan (penilaian teknologi kesehatan [HTA] atau non-HTA).
- Alat AI/ML yang digunakan dan fase peninjauan.
- Bidang (perawatan kesehatan atau kesejahteraan sosial).
2.3 Paparan
Paparan utama adalah penggunaan alat AI/ML sebagaimana direkomendasikan oleh tim AI/ML versus tidak digunakan sama sekali. Selain itu, kami membandingkan penggunaan yang tidak direkomendasikan versus penggunaan yang direkomendasikan, dan tidak digunakan versus penggunaan apa pun. Kami membedakan antara penggunaan yang direkomendasikan dan tidak direkomendasikan karena, lima belas bulan setelah tim AI/ML terbentuk, kami melihat pengulas menggunakan AI/ML bersamaan, alih-alih, proses manual. Misalnya, beberapa pengulas akan menggunakan algoritme pemeringkatan untuk menyaring judul dan abstrak, mencapai “dataran tinggi” yang menunjukkan semua studi relevan telah diidentifikasi, tetapi kemudian terus menyaring secara manual ribuan studi yang tersisa dan kemungkinan tidak relevan. Hal ini tidak diharapkan dapat menghemat sumber daya atau waktu.
Penggunaan AI/ML yang direkomendasikan didefinisikan sebagai penggunaan AI/ML dalam setiap fase peninjauan yang konsisten dengan panduan tim (lihat juga Penyimpangan Protokol). ML yang tidak direkomendasikan didefinisikan sebagai penggunaan AI/ML yang menyimpang dari panduan. Prinsip menyeluruh yang kami terapkan untuk mengklasifikasikan paparan adalah bahwa penggunaan AI/ML yang direkomendasikan menggantikan daripada melengkapi aktivitas manusia yang ada. Penggunaan AI/ML yang tidak direkomendasikan didefinisikan sebagai penggunaan AI/ML dalam setiap fase peninjauan yang tidak mengikuti panduan (misalnya, bersamaan dengan proses manual). Setiap penggunaan AI/ML didefinisikan sebagai penggunaan AI/ML dalam setiap fase peninjauan yang mengikuti atau tidak mengikuti panduan. Tidak menggunakan AI/ML didefinisikan sebagai tidak menggunakan AI/ML dalam setiap fase peninjauan.
Definisi ini mengakibatkan setiap ulasan diklasifikasikan ke dalam satu atau beberapa paparan. Misalnya, ulasan yang diklasifikasikan sebagai ulasan yang menggunakan AI/ML yang direkomendasikan juga akan menggunakan AI/ML apa pun. Oleh karena itu, jumlah ulasan yang disertakan dalam perbandingan di atas bervariasi.
Klasifikasi paparan dilakukan oleh dua peneliti (JFME dan AEM) tanpa melihat hasil. Klasifikasi dilakukan menggunakan teks tinjauan akhir dan informasi yang tercatat dalam blog proyek yang digunakan tim AI/ML untuk mendokumentasikan dukungan yang diberikan kepada tim peninjau.
Alat AI/ML yang digunakan oleh NIPH mencakup empat kategori besar: alat pemeringkatan (misalnya, penyaringan prioritas dalam EPPI-Reviewer), alat klasifikasi (misalnya, pengklasifikasi desain studi untuk RCT dan untuk tinjauan sistematis), alat pengelompokan (misalnya, Lingo3G), dan alat bibliografi bertenaga AI/ML (khususnya, OpenAlex).
2.4 Hasil
Penggunaan sumber daya didefinisikan sebagai jumlah jam-orang yang dicatat terhadap tinjauan dari komisi hingga penyelesaian atau tanggal batas waktu. Waktu yang dibutuhkan oleh komisioner Norwegia untuk berunding tentang tinjauan yang telah selesai sebelum mengizinkan NIPH untuk menerbitkan bervariasi antara dua dan 8 minggu dan mungkin ada penundaan yang tidak dicatat oleh NIPH. Oleh karena itu, kami mendefinisikan hasil waktu-hingga- penyelesaian , bukan waktu-hingga- publikasi , untuk mencegah munculnya varians yang tidak perlu dalam hasil ini. Waktu-hingga-penyelesaian dihitung sebagai jumlah minggu dari komisi hingga persetujuan untuk pengiriman ke komisioner, termasuk waktu yang digunakan pada tinjauan sejawat; atau, untuk proyek yang sedang berlangsung pada batas waktu, jumlah minggu hingga tanggal batas waktu. Oleh karena itu, proyek yang sedang berlangsung disensor ke kanan sehubungan dengan penggunaan sumber daya dan waktu-hingga-penyelesaian.
2.5 Analisis Statistik
Kecuali sebagaimana dicatat dalam Penyimpangan Protokol, analisis statistik dilakukan sebagaimana ditentukan sebelumnya dalam protokol kami [ 24 ]. Ahli statistik (CJR) tidak mengetahui klasifikasi paparan hingga analisis diselesaikan. Karena tinjauan tidak ditetapkan secara acak untuk menggunakan AI/ML yang direkomendasikan versus tanpa AI/ML, kami berencana untuk memodelkan dan dengan demikian memperhitungkan penetapan endogen (nonacak) menggunakan variabel bidang (perawatan kesehatan atau kesejahteraan) dan praspesifikasi (keberadaan protokol). Kami mengantisipasi bahwa tinjauan yang tidak berencana untuk melakukan meta-analisis (misalnya, sintesis kualitatif) menggunakan lebih sedikit sumber daya dan dapat diselesaikan dalam waktu yang lebih singkat. Oleh karena itu, kami berencana untuk menyesuaikan penggunaan meta-analisis yang direncanakan dalam semua analisis.
Ulasan yang sedang berlangsung disensor tepat pada batas waktu studi dan semua analisis memperhitungkan penyensoran ini. Kami tidak memiliki alasan untuk mencurigai adanya penyensoran informatif (nonacak), jadi tidak memodelkan mekanisme penyensoran. Penggunaan sumber daya dianalisis menggunakan regresi interval yang diperluas [ 26 , 27 ]. Waktu penyelesaian dianalisis menggunakan model penyesuaian regresi tertimbang-probabilitas-terbalik yang disesuaikan dengan kemungkinan [ 28 ]. Normalitas residual dinilai menggunakan uji Shapiro-Wilk.
Untuk membantu generalisasi ke institusi lain, kami mengekspresikan kembali estimasi sebagai penggunaan sumber daya relatif dan waktu penyelesaian relatif dengan mengeksponensialkan perbedaan dalam logaritma penggunaan sumber daya, dan dengan menghitung rasio waktu penyelesaian rata-rata menggunakan metode delta [ 29 ]. Kami menyajikan interval kepercayaan 95% dua sisi dan nilai- p jika sesuai dan menggunakan kriteria signifikansi p < 0,05 yang telah ditentukan sebelumnya secara menyeluruh. Kami juga meringkas data waktu penyelesaian menggunakan estimasi Kaplan-Meier dari fungsi survivor (perhatikan bahwa ini tidak memperhitungkan penugasan pengobatan endogen nonacak dan tidak disesuaikan). Analisis statistik dilakukan menggunakan Stata 18 (StataCorp LLC, College Station, Texas, AS).
2.6 Penilaian Risiko Bias Prospektif
Kami menggunakan alat Risk Of Bias In Non-randomized Studies of Interventions (ROBINS-I) [ 30 ] saat menulis protokol untuk mengantisipasi dan mengurangi risiko bias, dan menilai bahwa studi tersebut akan memiliki risiko bias yang rendah. Meskipun ROBINS-I dikembangkan untuk digunakan dalam menilai studi yang dilaporkan, kami menganggap alat ini dan alat terkait sangat berharga untuk mengidentifikasi kemungkinan keterbatasan metodologis pada tahap protokol.
2.7 Penyimpangan Protokol
Tidak mungkin untuk memodelkan penugasan perawatan endogen menggunakan kedua variabel yang telah ditentukan sebelumnya (lapangan dan praspesifikasi) dalam analisis penggunaan sumber daya karena modelnya tidak konvergen. Oleh karena itu, kami menggunakan salah satu dari dua variabel, memilih variabel dengan standar error terkecil dalam model penugasan (sementara disamarkan). Penugasan endogen dari AI/ML apa pun atau yang direkomendasikan dimodelkan oleh lapangan (kajian kesejahteraan umumnya lebih cenderung menggunakan AI/ML) dan penggunaan AI/ML yang direkomendasikan dimodelkan oleh praspesifikasi (kajian dengan protokol umumnya lebih kecil kemungkinannya untuk menggunakan AI/ML yang direkomendasikan).
Selama ekstraksi data, kami melihat bahwa mungkin ada dua bentuk penggunaan AI/ML yang tidak direkomendasikan: penggunaan AI/ML yang kurang dan berlebihan. Oleh karena itu, kami menerbitkan protokol yang diperbarui sebagai pracetak selama ekstraksi data tetapi sebelum memulai analisis atau membuka kebutaan ahli statistik untuk mendefinisikan ulang paparan untuk mempertimbangkan kedua bentuk penggunaan AI/ML yang tidak direkomendasikan ini [ 31 ]. Namun, terlalu sedikit ulasan yang dinilai telah menggunakan AI/ML yang kurang atau berlebihan, sehingga tidak mungkin untuk menjalankan analisis ini. Oleh karena itu, kami melakukan dan melaporkan analisis seperti yang direncanakan semula.
2.8 Pelaporan
Kami mengikuti pedoman pelaporan Penguatan Pelaporan Studi Observasional dalam Epidemiologi (STROBE) [ 32 ] (lihat Daftar Periksa S1 ).
3 Hasil
3.1 Ulasan yang disertakan
Tabel 1 merangkum karakteristik tinjauan yang disertakan. Pada tahap protokol, kami mengantisipasi untuk menyertakan sekitar 100 tinjauan berdasarkan batas waktu studi tetapi hanya dapat menyertakan 39. Ini karena kami ditugaskan untuk menghasilkan lebih banyak laporan yang tidak memenuhi syarat daripada yang diantisipasi (misalnya, laporan yang bukan tinjauan, atau yang berencana untuk menggunakan meta-analisis jaringan) dan lebih sedikit tinjauan secara keseluruhan karena pemotongan anggaran dan perampingan setelah pandemi COVID-19. Dari 39 tinjauan, 7 (19%) adalah penilaian teknologi kesehatan versus tinjauan sistematis, 19 (49%) ditugaskan pada topik perawatan kesehatan versus kesejahteraan, 18 (46%) berencana untuk melakukan meta-analisis, 27 (69%) menggunakan segala bentuk AI/ML, dan 3 (8%) sedang berlangsung (disensor) pada batas waktu.
| Paparan utama | Paparan tambahan | |||||
|---|---|---|---|---|---|---|
| Tidak Menggunakan AI/ML | Penggunaan AI/ML yang Direkomendasikan | Penggunaan AI/ML yang Tidak Direkomendasikan | Penggunaan AI/ML yang Direkomendasikan | Tidak Menggunakan AI/ML | Segala Penggunaan AI/ML | |
| Ulasan yang ditugaskan | 12/39 (31%) | 21/39 (54%) | 6/39 (15%) | 21/39 (54%) | 12/39 (31%) | 27/39 (69%) |
| Ulasan yang sudah selesai | 12/39 (31%) | 19/39 (49%) | 5/39 (13%) | 19/39 (49%) | 12/39 (31%) | 24/39 (62%) |
| Jenis ulasan | ||||||
| Penilaian teknologi kesehatan (HTA) | 3/39 (8%) | 2/39 (5%) | 2/39 (5%) | 2/39 (5%) | 3/39 (8%) | 4/39 (10%) |
| Non-HTA | 9/39 (23%) | 19/39 (49%) | 4/39 (10%) | 19/39 (49%) | 9/39 (23%) | 23/39 (59%) |
| Jenis sintesis yang direncanakan | ||||||
| Apa pun (kuantitatif atau kualitatif) | 11/39 (28%) | 19/39 (49%) | 6/39 (15%) | 19/39 (49%) | 11/39 (28%) | 25/39 (64%) |
| Meta-analisis berpasangan | 4/39 (10%) | 10/39 (26%) | 4/39 (10%) | 10/39 (26%) | 4/39 (10%) | 14/39 (36%) |
| Meta-analisis jaringan | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
| AI/ML digunakan selama identifikasi studi | ||||||
| Peringkat | angka 0 | 19/39 (49%) | 6/39 (15%) | 19/39 (49%) | angka 0 | 25/39 (64%) |
| Klasifikasi | angka 0 | 9/39 (23%) | 3/39 (8%) | 9/39 (23%) | angka 0 | 12/39 (31%) |
| Kekelompokan | angka 0 | 6/39 (15%) | 2/39 (5%) | 6/39 (15%) | angka 0 | 8/39 (21%) |
| Buka Alex | angka 0 | 5/39 (13%) | angka 0 | 5/39 (13%) | angka 0 | 5/39 (13%) |
| AI/ML digunakan selama ekstraksi data | ||||||
| Klasifikasi | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
| Kekelompokan | angka 0 | 1/39 (3%) | angka 0 | 1/39 (3%) | angka 0 | 1/39 (3%) |
| Ekstraksi data otomatis | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
| Fungsi AI/ML lainnya | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 | angka 0 |
Catatan: Data adalah jumlah ulasan dan persentase semua ulasan yang disertakan.
3.2 Hubungan Penggunaan AI/ML dengan Penggunaan Sumber Daya dan Waktu Penyelesaian
Hasil studi dirangkum dalam Tabel 2. Gambar 1 menyajikan plot Kaplan-Meier untuk waktu penyelesaian. Rata-rata, ulasan yang menggunakan AI/ML seperti yang direkomendasikan menggunakan lebih banyak sumber daya daripada yang tidak (667 vs. 291 jam-orang; penggunaan sumber daya relatif 3,71; 95% CI: 0,36 hingga 37,95; p = 0,269) tetapi diselesaikan lebih cepat (27,6 vs. 28,2 minggu; waktu penyelesaian relatif 0,92; 95% CI: 0,53 hingga 1,58; p = 0,753). Tidak ada estimasi efek yang cukup tepat untuk menyimpulkan bahwa penggunaan AI/ML yang direkomendasikan atau apa pun dikaitkan dengan penggunaan sumber daya yang lebih banyak atau lebih sedikit, atau waktu penyelesaian yang lebih lama atau lebih pendek, dibandingkan dengan tidak ada atau tidak ada penggunaan AI/ML yang direkomendasikan. Untuk penggunaan sumber daya, estimasi titik lebih mengutamakan penggunaan AI/ML yang direkomendasikan daripada penggunaan AI/ML yang tidak direkomendasikan, dan penggunaan AI/ML apa pun daripada tidak menggunakan AI/ML, sementara tidak menggunakan AI/ML lebih diutamakan daripada penggunaan AI/ML yang direkomendasikan. Untuk waktu penyelesaian, estimasi titik lebih mengutamakan penggunaan AI/ML yang direkomendasikan dan apa pun daripada tidak menggunakan AI/ML, sementara penggunaan AI/ML yang tidak direkomendasikan lebih diutamakan daripada penggunaan AI/ML yang direkomendasikan.
| Paparan (Jenis Penggunaan AI/ML) | Ulasan a | Rata-rata (SD) b | Estimasi efek c | nilai p |
|---|---|---|---|---|
| Penggunaan sumber daya | Jam kerja orang | Penggunaan sumber daya relatif | ||
| Paparan utama | ||||
| Tidak Menggunakan AI/ML | 12/33 (36%) | 291 (379) | 3,71 (0,36 hingga 37,95) | 0.269 |
| Penggunaan AI/ML yang Direkomendasikan | 21/33 (64%) | 667 (367) | ||
| Paparan tambahan | ||||
| Penggunaan AI/ML yang Tidak Direkomendasikan | 6/27 (22%) | 1158 (893) | 0,50 (0,02 hingga 10,74) | 0.658 |
| Penggunaan AI/ML yang Direkomendasikan | Tahun 21/27 (78%) | 667 (367) | ||
| Tidak Menggunakan AI/ML | 12/39 (31%) | 291 (379) | 0,65 (0,22 hingga 1,93) | 0.439 |
| Segala Penggunaan AI/ML | 27/39 (69%) | 769 (534) | ||
| Waktu penyelesaian | Minggu | Waktu relatif untuk penyelesaian | ||
| Paparan utama | ||||
| Tidak Menggunakan AI/ML | 12/33 (36%) | 28.2 (31.1) | 0,92 (0,53 hingga 1,58) | 0.753 |
| Penggunaan AI/ML yang Direkomendasikan | 21/33 (64%) | 27.6 (15.4) | ||
| Paparan tambahan | ||||
| Penggunaan AI/ML yang Tidak Direkomendasikan | 6/27 (22%) | 36.2 (26.4) | 1.12 (0,67 hingga 1,89) | 0.658 |
| Penggunaan AI/ML yang Direkomendasikan | Tahun 21/27 (78%) | 27.6 (15.4) | ||
| Tidak Menggunakan AI/ML | 12/39 (31%) | 28.2 (31.1) | 0,93 (0,58 hingga 1,51) | 0.784 |
| Segala Penggunaan AI/ML | 27/39 (69%) | 29.5 (18.0) |
a Penyebut bervariasi berdasarkan perbandingan karena ulasan mungkin tidak memenuhi definisi paparan.
b Data merupakan rata-rata (simpangan baku) sampel yang dibatasi pada tinjauan yang telah selesai (tanpa sensor) dan tidak memperhitungkan alokasi perawatan endogen nonacak.
c Estimasi efek memperhitungkan hasil yang disensor kanan, alokasi perawatan endogen nonacak, dan disesuaikan dengan meta-analisis yang direncanakan. Estimasi efek < 1 menunjukkan bahwa penggunaan AI/ML yang direkomendasikan atau apa pun dikaitkan dengan penggunaan sumber daya yang lebih sedikit atau waktu penyelesaian yang lebih singkat dibandingkan dengan pembanding.
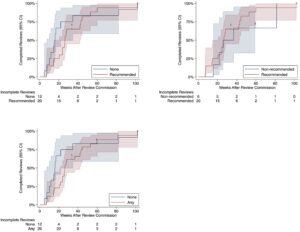
Perkiraan asosiasi umumnya konsisten dengan rata-rata sampel. Namun, rata-rata sampel mungkin menyesatkan karena kemungkinan faktor pengganggu akibat penugasan paparan nonacak, tidak memperhitungkan penyensoran tinjauan yang sedang berlangsung, dan tidak disesuaikan dengan efek meta-analisis yang direncanakan, yang dikaitkan dengan penggunaan sumber daya yang lebih banyak dan waktu penyelesaian yang lebih lama.
4 Diskusi
4.1 Temuan
Studi ini tidak mengidentifikasi perbedaan yang signifikan secara statistik dalam penggunaan sumber daya atau waktu penyelesaian sehubungan dengan perbandingan antara paparan utama atau tambahan. Estimasi titik untuk penggunaan sumber daya lebih menyukai AI/ML yang direkomendasikan daripada yang tidak direkomendasikan, dan penggunaan AI/ML apa pun daripada tidak ada penggunaan AI/ML. Namun, estimasi titik untuk penggunaan AI/ML yang direkomendasikan versus tidak ada penggunaan AI/ML lebih menyukai yang terakhir. Dengan asumsi ini benar, kami berspekulasi bahwa tinjauan yang tidak menggunakan AI/ML mungkin lebih sederhana (dapat diselesaikan dengan menggunakan lebih sedikit sumber daya), lebih mendesak (tekanan untuk menggunakan lebih sedikit sumber daya), mungkin dilakukan dengan kurang ketat (karenanya menggunakan lebih sedikit sumber daya) daripada yang mengikuti rekomendasi tim AI/ML, dan bahwa kami tidak dapat memperhitungkan hal ini dalam analisis. Untuk waktu penyelesaian, estimasi titik lebih menyukai AI/ML yang direkomendasikan daripada tidak ada penggunaan AI/ML, dan penggunaan AI/ML apa pun daripada tidak ada penggunaan AI/ML. Namun, estimasi titik untuk penggunaan AI/ML yang direkomendasikan versus yang tidak direkomendasikan lebih menyukai penggunaan AI/ML yang tidak direkomendasikan. Kami telah mengamati dua bentuk penggunaan AI/ML yang tidak direkomendasikan (lihat Penyimpangan Protokol), yang salah satunya diperkirakan akan menyebabkan waktu penyelesaian yang lebih singkat dan dapat menjelaskan temuan ini.
Ada kemungkinan bahwa varians substansial dalam hasil keseluruhan yang kami pelajari diperkenalkan oleh fase-fase tinjauan yang tidak dapat diotomatisasi ketika tinjauan dilakukan, seperti analisis, GRADEing [ 33 ], penulisan laporan, dan tinjauan sejawat. Munculnya model bahasa yang besar [ 34 ] dapat mewakili peluang untuk mengotomatisasi dan mempercepat fase-fase ini dan dengan demikian mengurangi penggunaan sumber daya secara keseluruhan dan waktu penyelesaian. Faktor-faktor lain, seperti tingkat literasi komputer yang berbeda dan kenyamanan menggunakan alat AI/ML juga diharapkan dapat memberikan varians yang mungkin sulit untuk disesuaikan tetapi melekat pada tugas seperti peninjauan sistematis yang dilakukan oleh peneliti dengan latar belakang pendidikan dan pengalaman yang beragam.
4.2 Kekuatan dan Keterbatasan
Kekuatan utama dari studi ini adalah sebagai berikut. Studi ini telah ditentukan sebelumnya dan dilakukan menurut protokol peer-review yang dipublikasikan, yang mencakup penilaian risiko bias ROBINS-I prospektif. Pekerjaan itu dilakukan hanya dengan penyimpangan protokol kecil, yang kami laporkan dan justifikasi. Kami menggunakan hasil yang mencerminkan keseluruhan biaya dan waktu produksi, yang lebih relevan daripada yang berfokus pada fase tinjauan individual dan yang mungkin tidak menghasilkan penghematan keseluruhan. Hasil ini didefinisikan menggunakan data internal yang biasanya tidak tersedia. Kami membuat tiga perbandingan yang relevan, menekankan penggunaan alat AI/ML menurut rekomendasi. Klasifikasi paparan dan analisis statistik dilakukan secara buta; yang mengatakan, ada kemungkinan bahwa pembutaan klasifikasi paparan tidak sempurna karena JFME terbiasa dengan beberapa tinjauan, jadi ini mungkin telah memperkenalkan bias. Akhirnya, kami menggunakan metode statistik yang tepat yang memperhitungkan penugasan paparan endogen (nonacak) dan penyensoran tinjauan yang sedang berlangsung.
Keterbatasan utama dari studi ini adalah desain non-acak retrospektif dan ukuran sampel yang lebih kecil dari yang diantisipasi. Sementara kami secara prospektif menilai studi tersebut berisiko rendah bias [ 24 ], kami mengantisipasi bahwa mungkin ada sisa pengganggu yang tidak dapat kami perhitungkan dalam analisis, dan ini mungkin telah terjadi. Ada kemungkinan bahwa beberapa tim peninjau menggunakan AI/ML tetapi tidak melaporkannya secara lengkap sesuai dengan pedoman pelaporan kami, dan ini mungkin telah menyebabkan beberapa kesalahan klasifikasi. Tidak ada penyimpangan protokol utama, meskipun perlu untuk mengubah bagaimana penugasan endogen dimodelkan untuk penggunaan sumber daya karena non-konvergensi, tetapi pilihan analisis ini dibuat sebelum ahli statistik tidak dibutakan. Kami mencoba untuk memperhitungkan fakta bahwa tinjauan mungkin telah menggunakan AI/ML yang kurang atau berlebihan, tetapi ini tidak mungkin (lihat Penyimpangan Protokol). Kami menggunakan tanggal komisi untuk menghitung waktu penyelesaian, tetapi ini mungkin telah memperkenalkan varians karena ada kemungkinan bahwa pekerjaan pada beberapa tinjauan tidak dimulai hingga jauh kemudian. Kami menyarankan agar penelitian di masa mendatang mempertimbangkan definisi alternatif (misalnya, tanggal penelusuran literatur pertama). Terakhir, batas administratif menghalangi penyertaan tinjauan yang telah menggunakan alat AI generatif seperti model bahasa besar, yang tidak tersedia secara luas selama periode penelitian, tetapi kami mengantisipasi akan memiliki utilitas substansial dalam sintesis bukti [ 35 , 36 ].
4.3 Kesimpulan
Hubungan antara penggunaan alat AI/ML untuk sintesis bukti dan penggunaan sumber daya serta waktu penyelesaian tidak jelas. Berdasarkan hasil studi ini, kami menyarankan studi mendatang diperkuat untuk mendeteksi pengurangan penggunaan sumber daya sebesar 30% atau lebih baik dan pengurangan waktu penyelesaian sebesar 10% atau lebih baik. Perhitungan daya informal menunjukkan studi nonacak mungkin memerlukan beberapa ratus tinjauan; uji coba acak akan lebih disukai tetapi mungkin tidak layak. Ini menunjukkan studi multisenter atau meta-analisis menggunakan bukti nonacak mungkin diperlukan. Kami menyarankan agar pekerjaan mendatang mempelajari efek atau hubungan AI/ML pada kualitas, ketepatan [ 36 ], validitas, dan reproduktifitas tinjauan, untuk memastikan bahwa adopsi otomatisasi tidak mengarah pada pengambilan keputusan yang kurang optimal atau kerugian lainnya, dan bahwa tinjauan, metodologi tinjauan, dan pemangku kepentingan mendapat manfaat dari teknologi baru. Studi ini kemungkinan akan memerlukan studi nonacak yang harus dengan hati-hati mengatasi masalah seperti penugasan endogen (nonacak) penggunaan atau nonpenggunaan AI/ML, seperti dalam makalah ini.