Abstrak
Slide histopatologi yang diwarnai hematoxylin dan eosin (H&E) mengandung banyak informasi tentang morfologi sel dan jaringan dan telah menjadi landasan diagnosis tumor selama beberapa dekade. Dalam beberapa tahun terakhir, kemajuan dalam patologi digital telah membuat gambar slide utuh (WSI) dapat diaplikasikan secara luas untuk diagnosis, prognosis, dan prediksi pada kanker otak. Namun, masih terdapat kekurangan alat sistematis dan protokol standar untuk menggunakan fitur buatan tangan dalam analisis histologis kanker otak. Dalam studi ini, kami menyajikan protokol untuk analisis fitur buatan tangan dalam patologi kanker otak (PHBCP) untuk mengekstraksi, menganalisis, memodelkan, dan memvisualisasikan fitur buatan tangan dari WSI secara sistematis. Protokol tersebut memungkinkan penemuan biomarker dari WSI melalui serangkaian langkah yang terdefinisi dengan baik. PHBCP terdiri dari tujuh langkah utama: (1) definisi masalah, (2) kontrol kualitas data, (3) praproses gambar, (4) ekstraksi fitur, (5) penyaringan fitur, (6) pemodelan, dan (7) analisis kinerja. Sebagai contoh aplikasi, kami mengumpulkan data patologis dari 589 pasien dari dua kelompok dan menerapkan PHBCP untuk memprediksi kelangsungan hidup 2 tahun pasien glioblastoma multiforme (GBM). Di antara 72 model yang menggabungkan sembilan metode pemilihan fitur dan delapan pengklasifikasi pembelajaran mesin, kombinasi model yang optimal mencapai kinerja diskriminatif dengan rata-rata area di bawah kurva (AUC) sebesar 0,615 selama 100 iterasi di bawah validasi silang lima kali lipat. Dalam kelompok validasi eksternal, kombinasi model yang optimal mencapai kinerja generalisasi dengan AUC sebesar 0,594. Kami menyediakan repositori kode sumber terbuka (situs web GitHub: https://github.com/XuanjunLu/PHBCP ) untuk memfasilitasi kolaborasi yang efektif antara pakar medis dan teknis, dengan demikian memajukan bidang patologi komputasional dalam kanker otak.
Poin-poin penting
Apa yang sudah diketahui tentang topik ini?
- Citra slide utuh (WSI) yang diwarnai hematoksilin dan eosin (H&E) mengandung banyak informasi tentang morfologi sel dan jaringan. Namun, masih belum ada alat sistematis dan protokol standar untuk menggunakan fitur buatan tangan dalam analisis histologis kanker otak.
Apa yang ditambahkan penelitian ini?
- Studi ini menyajikan protokol untuk analisis fitur buatan tangan dalam patologi kanker otak untuk secara sistematis mengekstraksi, menganalisis, memodelkan, dan memvisualisasikan fitur buatan tangan dari WSI, sehingga mendorong kolaborasi yang efisien antara ahli medis dan teknis.
1. PENDAHULUAN
Kaca film histopatologi, yang dikenal sebagai “standar emas” untuk diagnosis tumor, 1 memiliki nilai penting tidak hanya dalam penilaian morfologi penyakit tetapi juga dalam informasi biomedis penting seperti heterogenitas tumor, karakteristik lingkungan mikro, dan fenotipe molekuler. 2 Dalam diagnosis dan pengobatan kanker otak, analisis histopatologi menggunakan kaca film yang diwarnai hematoksilin dan eosin (H&E) memberikan bukti diagnostik yang sangat diperlukan untuk pengambilan keputusan klinis. Namun, alur kerja diagnostik tradisional bergantung pada inspeksi visual kaca film oleh ahli patologi di bawah mikroskop dari perbesaran rendah hingga tinggi. Pendekatan analitis kualitatif ini memiliki keterbatasan yang melekat. Pertama, interpretasi subjektif rentan terhadap variabilitas karena perbedaan pengalaman, yang menyebabkan ketidakkonsistenan diagnostik. 3 Kedua, pemeriksaan konvensional mengalami kesulitan dalam mengekstraksi fitur jaringan subvisual secara kuantitatif, yang mungkin mencakup informasi prognosis penting. 4 Ketiga, hambatan efisiensi analisis manual menjadi jelas ketika menangani sejumlah besar kaca film. 5 Dengan demikian, protokol yang akurat, objektif, dan dapat ditafsirkan merupakan tujuan penting dalam patologi kanker otak.
Dalam beberapa tahun terakhir, pengembangan teknologi citra slide utuh (WSI) yang didigitalkan telah merevolusi bidang patologi dengan memungkinkan penyimpanan digital permanen dari slide histopatologi. 6 Dengan memanfaatkan WSI, fitur yang dibuat dengan tangan—yaitu, fitur yang diekstraksi oleh algoritma yang dirancang secara manual yang dipandu oleh pengetahuan awal khusus domain dan keahlian empiris—telah digunakan untuk mengekstrak atribut untuk penemuan biomarker. Fitur-fitur ini dapat memperoleh informasi prognostik, prediktif, dan patologis kuantitatif lainnya dari WSI yang diwarnai H&E, yang berpotensi mengubah onkologi presisi dan meningkatkan hasil pasien. Selama beberapa tahun terakhir, biomarker berdasarkan fitur yang dibuat dengan tangan telah diterapkan secara luas dalam berbagai kanker, termasuk karsinoma sel skuamosa kepala dan leher, 7 kanker urotelial, 8 karsinoma tiroid papiler, 9 karsinoma hepatoseluler, 10 , 11 kanker paru-paru, 12 , 13 karsinoma sel skuamosa orofaringeal, 14 dan kanker kolorektal. 15 Namun, penerapannya pada kanker otak masih kurang dan jarang dilaporkan dalam literatur.
Penelitian kanker otak saat ini terutama berfokus pada citra radiologi, 16 – 19 dengan sedikit penelitian yang didedikasikan untuk analisis histopatologi. Bahkan dalam investigasi patologis yang terbatas, pendekatan pembelajaran mendalam mendominasi, 20 namun sifat “kotak hitam” mereka mengakibatkan kurangnya interpretabilitas, yang secara signifikan menghambat penerapan klinis yang lebih luas. Persyaratan sumber daya komputasi yang substansial dan alur kerja praproses yang rumit yang terkait dengan model pembelajaran mendalam menimbulkan hambatan tambahan, yang selanjutnya membatasi aksesibilitas dan adopsi praktis mereka dalam pengaturan klinis.
Dalam studi ini, kami menyajikan protokol untuk analisis fitur buatan tangan dalam patologi kanker otak (PHBCP) berdasarkan WSI yang diwarnai H&E. Protokol tersebut merupakan alur kerja sumber terbuka yang sederhana, fleksibel, dan modular. Kami mendemonstrasikan penggunaan protokol tersebut menggunakan dua kelompok glioblastoma multiforme (GBM). Dengan mengikuti protokol ini, para ahli medis dan teknis akan mampu meningkatkan komunikasi dan kolaborasi, mengembangkan biomarker baru, dan secara kolektif mengatasi tantangan klinis dalam kanker otak, yang pada akhirnya meningkatkan hasil pasien.
2 METODE
2.1 Tinjauan Umum Protokol
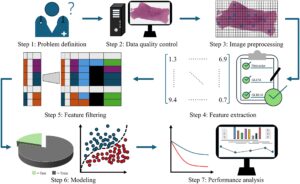
Protokol ini terdiri dari tujuh langkah utama (Gambar 1 ): (1) definisi masalah, (2) kontrol kualitas data, (3) praproses gambar, (4) ekstraksi fitur, (5) pemfilteran fitur, (6) pemodelan, dan (7) analisis kinerja. Langkah definisi masalah menentukan tujuan klinis yang tepat untuk dianalisis. Langkah kontrol kualitas data bertujuan untuk menghilangkan slide yang mengandung kontaminasi, artefak, dan masalah lainnya. Langkah praproses gambar menyediakan proses praproses standar berbasis WSI, yang mencakup akuisisi region of interest (ROI), WSI slicing, dan normalisasi warna. Langkah ekstraksi fitur merinci jenis, peran, ekstraksi, dan pendekatan agregasi untuk fitur buatan tangan. Langkah pemfilteran fitur menyempurnakan sekumpulan besar fitur redundan untuk mengidentifikasi fitur yang paling relevan dengan label. Langkah pemodelan melibatkan konstruksi model berdasarkan fitur yang difilter untuk mencapai kinerja analitis yang optimal. Terakhir, langkah analisis kinerja memvisualisasikan fitur penting dan melakukan analisis hilir. Dalam studi ini, kami menggunakan WSI yang diwarnai H&E dari dua kelompok independen [The Cancer Genome Atlas (TCGA) dan The Cancer Imaging Archive (TCIA)] 21 untuk menunjukkan cara menggunakan PHBCP. Keunikan protokol ini terletak pada penggunaan fitur buatan tangan yang dapat ditafsirkan, bukan pembelajaran mendalam, untuk menetapkan hubungan kompleks antara WSI dan pertanyaan klinis. Selanjutnya, Bagian 3.2 – 3.8 masing-masing sesuai dengan langkah 1–7.
2.2 Definisi masalah
Pertama, masalah klinis ditentukan, diikuti dengan pengumpulan sampel jaringan dan laporan patologi terkait dari pasien. Operasi pemotongan dan pewarnaan dilakukan pada sampel jaringan. Kaca jaringan yang diwarnai diubah menjadi gambar histologi kaca utuh digital menggunakan pemindai digital untuk analisis patologi komputasional berikutnya. Misalnya, seseorang mungkin ingin menyelidiki hubungan antara fitur bentuk inti dan tingkat tumor sistem saraf pusat.
2.3 Kontrol kualitas data
WSI yang dikumpulkan dapat dipindai oleh beragam personel klinis yang menggunakan pemindai berbeda di berbagai institusi, yang pasti menghasilkan kualitas gambar yang heterogen. Untuk mengurangi potensi pengaruh variabel eksternal ini pada hasil eksperimen, perlu untuk mengecualikan slide di bawah standar. Namun, pemeriksaan manual kualitas gambar dalam konteks eksperimen throughput tinggi sering kali tidak layak. Akibatnya, alat yang disebut HistoQC 22 biasanya digunakan sebagai proses kontrol kualitas yang objektif dan cepat, mengidentifikasi dan menandai masalah seperti kontaminasi reagen, artefak, lipatan jaringan, dan ketidakteraturan pewarnaan, sehingga memungkinkan penilaian otomatis kualitas WSI. Dikombinasikan dengan penampil gambar patologis-QuPath, 23 data di bawah standar dikecualikan. Efek batch multisenter, seperti variasi pewarnaan, yang dapat memengaruhi kekokohan model. Disarankan untuk menggunakan Batch Effect Explorer 24 untuk mengungkap efek batch antar kelompok.
2.4 Praproses Gambar
Bahasa Indonesia : Di Bagian 2.3 , kami membuat masker jaringan, yang mengecualikan artefak, lipatan jaringan, dan pengaruh eksternal lainnya. Pada langkah ini, ROI dari tugas saat ini diekstraksi dari masker jaringan dan dibagi menjadi petak gambar dengan ukuran dan perbesaran yang diinginkan, misalnya, 224 × 224 piksel pada perbesaran 20x, menggunakan pustaka OpenSlide, 25 yang merupakan pustaka Python yang digunakan untuk memproses WSI. Untuk memastikan distribusi jaringan yang relatif padat, hanya petak gambar yang berisi lebih dari proporsi tertentu dari area jaringan yang dipilih, misalnya, dengan 80% area jaringan. Untuk mengurangi beban komputasi dan menghindari bias seleksi subjektif, pengelompokan K -means dilakukan pada petak setiap WSI untuk mengelompokkan petak dengan fenotipe yang sama bersama-sama. Untuk memastikan tidak ada daerah kritis yang terlewatkan, petak E dipilih dari setiap klaster, sehingga petak L × E digunakan untuk mengkarakterisasi setiap pasien, di mana L adalah jumlah klaster. Karena variasi pewarnaan di berbagai pusat, normalisasi warna berbasis dekonvolusi 26 – 28 diterapkan pada ubin yang dipilih untuk menghilangkan perbedaan warna antara WSI.
2.5 Ekstraksi fitur
Ekstraksi fitur mengacu pada proses mengubah gambar menjadi nilai fitur yang dideskripsikan secara kuantitatif. Lima jenis fitur buatan tangan disediakan dalam protokol ini: statistik orde pertama ( n = 17), fitur matriks ko-kemunculan tingkat abu-abu (GLCM) ( n = 24), fitur matriks panjang lari tingkat abu-abu (GLRLM) ( n = 16), fitur bentuk nuklir ( n = 25), dan fitur tekstur nuklir ( n = 13). Statistik orde pertama menggambarkan distribusi nilai intensitas piksel dalam wilayah jaringan. Fitur GLCM mengkarakterisasi frekuensi pasangan nilai intensitas piksel yang identik di wilayah jaringan. Fitur GLRLM menggambarkan kontinuitas nilai intensitas piksel pada jarak tertentu di wilayah jaringan. Fitur bentuk nuklir digunakan untuk mengukur sifat geometris kontur nuklir, dengan demikian mencerminkan pola karakteristik deformasi nuklir dan perubahan morfologi seluler selama perkembangan tumor. Fitur tekstur nukleus, dengan mengukur heterogenitas dan konfigurasi spasial distribusi kromatin dalam nukleus, memungkinkan analisis mendalam tentang distorsi struktural dalam lingkungan mikro intranukleus selama evolusi tumor. Secara total, 95 fitur dapat diekstraksi untuk setiap petak gambar. Rincian dari lima jenis fitur adalah sebagai berikut:
Statistik orde pertama 29 :











Fitur-fitur lainnya, termasuk entropi, energi, korelasi, ukuran informasional korelasi 1, dan ukuran informasional korelasi 2, berasal dari fitur-fitur GLCM. Perhatikan bahwa ada jenis-jenis fitur buatan tangan lainnya, seperti interaksi spasial antara primitif histologis, 32 , 33 yang dapat diintegrasikan ke dalam PHBCP.
Singkatnya, untuk setiap WSI, matriks fitur berukuran ( L × E ) × N dapat diperoleh, di mana N adalah jumlah total fitur yang diekstraksi. Berdasarkan hal ini, pengguna dapat menggabungkan dan menggabungkan fitur menggunakan berbagai metode sesuai dengan kebutuhan mereka, misalnya, rata-rata, deviasi standar, dan kemiringan.
2.6 Penyaringan fitur
Pemfilteran fitur merupakan langkah penting dalam pembelajaran mesin yang mengidentifikasi fitur yang paling relevan dan informatif dari matriks fitur sekaligus menghilangkan fitur yang berlebihan dan tidak relevan. Proses ini tidak hanya mengurangi dimensionalitas fitur tetapi juga mengurangi overfitting, meningkatkan interpretabilitas model, dan meningkatkan efisiensi komputasi. Dalam studi ini, protokol menggunakan metode pemilihan fitur yang komprehensif untuk memastikan fitur yang tangguh dan andal.
Pertama, untuk mengatasi multikolinearitas dan mengurangi redundansi fitur, PHBCP menghitung matriks koefisien korelasi peringkat Spearman berpasangan di antara semua fitur. Fitur dengan koefisien korelasi lebih besar dari ambang batas, misalnya, 0,9 umumnya digunakan untuk menghilangkan fitur yang memiliki lebih dari 90% sinkronisitas, dihilangkan. Selanjutnya, matriks fitur distandarisasi menggunakan metode Z-score. 34 Langkah-langkah di atas memastikan bahwa hanya fitur yang tidak redundan yang disimpan untuk analisis lebih lanjut.
Kedua, protokol ini menggunakan metode pemilihan fitur yang komprehensif untuk menangkap berbagai aspek dari pentingnya fitur dan interaksinya. Metode-metode ini meliputi regresi Lasso (LR), hutan acak (RF), jaring elastis (EN), eliminasi fitur rekursif (RFE), analisis univariat (UA), relevansi maksimum redundansi minimum (MRMR), uji- t , uji jumlah peringkat Wilcoxon (WRST), dan metode informasi bersama (MI), yang diimplementasikan dalam Python menggunakan pustaka scikit-learn, mrmr_selection, dan scipy. Di sini, pengguna dapat memilih sejumlah fitur yang sesuai berdasarkan ukuran sampel untuk mencapai kinerja prediktif yang sesuai dan menghindari overfitting dan kutukan dimensionalitas.
Terakhir, setiap metode pemilihan fitur diintegrasikan dengan pengklasifikasi, dan validasi silang multi-lipat dengan iterasi yang ditentukan pengguna dilakukan untuk menilai konsistensi dan keandalan fitur yang dipilih di beberapa pemisahan data.
Dengan menggabungkan penyaringan berbasis korelasi dengan metode pemilihan fitur yang komprehensif dan validasi silang, protokol ini menyediakan kerangka kerja yang kuat untuk mengidentifikasi fitur yang paling diskriminatif sambil meminimalkan redundansi dan overfitting.
2.7 Pemodelan
Pada langkah ini, PHBCP menggabungkan metode pemilihan fitur dan pengklasifikasi satu per satu untuk membangun model potensial. Protokol ini menggunakan delapan pengklasifikasi pembelajaran mesin, termasuk analisis diskriminan kuadratik (QDA), analisis diskriminan linier (LDA), RF, K-nearest neighbor (KNN), linear support vector machine (LSVM), Gaussian naive bayes (GNB), stochastic gradient descent (SGD), dan adaptive boosting (AdaBoost), yang diimplementasikan dalam Python menggunakan pustaka scikit-learn. Delapan pengklasifikasi diimplementasikan bersama dengan fitur-fitur teratas yang dipilih menggunakan sembilan metode pemilihan fitur. Pengklasifikasi dievaluasi dengan validasi silang multi-lipat dengan iterasi yang ditentukan pengguna dalam kelompok pelatihan. Pada akhirnya, PHBCP mengidentifikasi kombinasi model optimal dari 72 kombinasi berbeda berdasarkan area rata-rata tertinggi di bawah kurva (AUC) di seluruh iterasi yang ditentukan pengguna.
2.8 Analisis kinerja
Berdasarkan kombinasi model optimal yang ditentukan selama fase pemodelan, seseorang dapat melakukan analisis kinerja dengan berfokus pada visualisasi distribusi fitur fitur utama, kepentingan fitur, dan analisis kelangsungan hidup dalam kohort validasi eksternal.
Pertama, PHBCP menghitung mean, median, dan skewness dari nilai fitur teratas, lalu membagi nilai fitur ke dalam bin yang sama untuk memperoleh 10 interval. Distribusi fitur teratas divisualisasikan menggunakan histogram yang dilapisi dengan kurva estimasi kepadatan kernel (Gaussian kernel). Kedua, batang horizontal digunakan untuk memvisualisasikan persentase frekuensi pemilihan fitur teratas di seluruh validasi silang multi-lipat dengan iterasi yang ditentukan pengguna, menyoroti fitur yang paling penting dan memahami kontribusinya terhadap kombinasi model yang optimal. Frekuensi pemilihan yang lebih tinggi menunjukkan kontribusi prediktif yang lebih besar pada model dan relevansi klinis yang lebih kuat dengan pertanyaan penelitian. Akhirnya, PHBCP mengunci kombinasi model yang optimal dan fitur teratas yang sesuai dalam kelompok pelatihan dan melakukan analisis kelangsungan hidup dalam kelompok validasi eksternal. Kurva Kaplan–Meier digunakan untuk mengevaluasi, misalnya, probabilitas kelangsungan hidup antara pasien yang diprediksi bertahan hidup jangka panjang dan jangka pendek. Uji log-rank digunakan untuk memeriksa perbedaan kelangsungan hidup, yang menunjukkan signifikansi prognostik variabel kategoris pada titik akhir kelangsungan hidup. Semua pengujian bersifat dua sisi, dengan tingkat signifikansi ditetapkan pada 0,05.
3 HASIL
Mengingat bahwa GBM adalah jenis tumor otak primer ganas yang paling umum dan agresif, 35 , 36 kami menggunakan masalah prediksi kelangsungan hidup GBM sebagai tugas contoh untuk menunjukkan cara menggunakan PHBCP. Pertama, data WSI dan informasi klinis dasar yang sesuai diperoleh dari dua kohort independen melalui The Cancer Genome Atlas (TCGA) (389 kasus) dan The Cancer Imaging Archive (TCIA, 200 kasus). 21 Selanjutnya, seluruh wilayah jaringan didefinisikan sebagai ROI, dengan kelangsungan hidup keseluruhan (OS) ditetapkan sebagai titik akhir. Untuk pasien yang kematiannya terjadi selama periode tindak lanjut, OS kurang dari atau sama dengan 2 tahun diklasifikasikan sebagai kelangsungan hidup jangka pendek, sedangkan OS lebih dari 2 tahun diklasifikasikan sebagai kelangsungan hidup jangka panjang. Untuk pasien yang disensor, waktu tindak lanjut akhir digunakan sebagai OS, dengan kasus yang OS-nya melebihi 2 tahun diklasifikasikan sebagai kelangsungan hidup jangka panjang, sedangkan kasus dengan OS kurang dari atau sama dengan 2 tahun dianggap sebagai informasi yang hilang dan dikeluarkan dari analisis. OS didefinisikan sebagai waktu dari operasi hingga kematian.
Dalam Bagian 2.3 , HistoQC digunakan untuk mengecualikan WSI dengan piksel yang dapat digunakan kurang dari 250.000 serta yang menunjukkan masalah signifikan seperti pengaburan yang luas, pelipatan jaringan, kontaminasi reagen, dan pewarnaan abnormal. Pengaturan terperinci disediakan dalam pengaturan parameter tambahan untuk HistoQC. Untuk pasien dengan beberapa slide, satu slide dipilih untuk analisis selanjutnya berdasarkan kualitas gambarnya menggunakan penampil gambar patologis-QuPath. Kriteria inklusi dan eksklusi diterapkan pada kedua kelompok. Kriteria inklusi: (1) pasien yang menjalani reseksi dan dipastikan memiliki GBM melalui spesimen patologis bedah; (2) pasien yang informasi OS-nya lengkap; (3) pasien yang berisi informasi tindak lanjut. Kriteria eksklusi: (1) WSI yang diwarnai H&E yang hilang dengan pembesaran 20x dan (2) slide histopatologi yang tidak memenuhi persyaratan standar untuk analisis. Akhirnya, 207 pasien dari TCGA dimasukkan sebagai kelompok pelatihan, sementara 57 pasien dari TCIA dimasukkan sebagai kelompok validasi eksternal. Tabel 1 menyajikan ringkasan informasi klinis dasar dan perbedaan distribusi antara kelompok pelatihan dan kelompok validasi eksternal.
| Kelompok pelatihan ( N = 207) | Kohort validasi eksternal ( N = 57) | P | |
|---|---|---|---|
| Usia | 0.8546 | ||
| ≤ 65 | 150 (72,5%) | 42 (73,7%) | |
| > 65 | 57 (27,5%) | 15 (26,3%) | |
| Seks | 0,9723 tahun | ||
| Pria | 124 (59,9%) | 34 (59,6%) | |
| Perempuan | 83 (40,1%) | 23 (40,4%) | |
| Balapan | <0.0001 | ||
| Putih | 189 (91,3%) | 24 (42,1%) | |
| Asia | 3 (1,4%) | 19 (33,3%) | |
| Lainnya | 11 (5,3%) | 13 (22,8%) | |
| Tidak dikenal | 4 (1,9%) | 1 (1,8%) | |
| Sejarah LGG | |||
| Ya | 3 (1,4%) | Bahasa Indonesia | |
| TIDAK | 204 (98,6%) | Bahasa Indonesia | |
| Status acara | 0.4987 | ||
| Muncul | 191 (92,3%) | 51 (89,5%) | |
| Disensor | 16 (7,7%) | 6 (10,5%) | |
| Status bertahan hidup | 0,5731 tahun | ||
| Jangka panjang (>2 tahun) | 54 (26,1%) | 17 (29,8%) | |
| Jangka pendek (≤2 tahun) | 153 (73,9%) | 40 (70,2%) | |
Nilai - p dihitung dengan uji Chi-square Pearson.
Pada Bagian 2.4 , masker jaringan yang dihasilkan melalui HistoQC disejajarkan dengan WSI yang sesuai, dan petak gambar berukuran 224 × 224 piksel diekstraksi pada perbesaran 20x tanpa tumpang tindih. Petak dari setiap WSI dikelompokkan menjadi 10 kelas, dan 50 petak dipilih secara acak dari setiap kelas untuk memastikan analisis menyeluruh dari semua wilayah. Normalisasi pewarnaan dilakukan pada 500 petak yang dipilih untuk ekstraksi fitur berikutnya.
Pada Bagian 2.5 , tiga jenis fitur diekstraksi: Statistik orde pertama, fitur GLCM, dan fitur GLRLM, dengan total 57 fitur. Untuk setiap WSI, matriks fitur berukuran 500 × 57 diperoleh, dan matriks fitur dirata-ratakan untuk menggabungkan vektor fitur berukuran 1 × 57.
Dalam Bagian 2.6 dan 2.7 , untuk menghindari kutukan dimensionalitas dan overfitting, kami menetapkan jumlah fitur teratas menjadi enam, berdasarkan pengalaman eksperimental bahwa jumlah fitur yang dipilih harus sekitar sepersepuluh dari jumlah sampel kelas minoritas. Dalam studi ini, kelompok pelatihan berisi 54 sampel kelas minoritas dan dengan demikian enam fitur teratas dipilih. Ambang korelasi Spearman ditetapkan menjadi 0,9. Kinerja prediktif model dalam kelompok pelatihan dievaluasi dengan melakukan 100 iterasi validasi silang lima kali lipat dalam 72 kombinasi model untuk menghindari hasil insidental. Hasil terperinci disajikan dalam Tabel 2. Tabel 2 menunjukkan bahwa kombinasi model yang optimal adalah MI-KNN (AUC = 0,615 ± 0,027). Hasil untuk akurasi dan skor F1 disajikan dalam Tabel S1 dan S2 , masing-masing.
| Tanya Jawab | LDA | Bahasa Indonesia: Frekuensi Radio | KNN | LSVM | GNB | SGD | AdaBoost | |
|---|---|---|---|---|---|---|---|---|
| Bahasa Indonesia: LR | 0,595 ± 0,022 | 0,550 ± 0,029 | 0,597 ± 0,037 | 0,591 ± 0,028 | 0,511 ± 0,034 | 0,601 ± 0,028 | 0,533 ± 0,038 | 0,610 ± 0,033 |
| Bahasa Indonesia: Frekuensi Radio | 0,593 ± 0,028 | 0,564 ± 0,025 | 0,586 ± 0,033 | 0,580 ± 0,029 | 0,521 ± 0,039 | 0,582 ± 0,030 | 0,536 ± 0,046 | 0,578 ± 0,032 |
| ID | 0,572 ± 0,029 | 0,547 ± 0,021 | 0,598 ± 0,038 | 0,579 ± 0,032 | 0,527 ± 0,034 | 0,567 ± 0,027 | 0,532 ± 0,038 | 0,584 ± 0,035 |
| Bahasa Inggris | 0,585 ± 0,032 | 0,509 ± 0,032 | 0,577 ± 0,036 | 0,583 ± 0,039 | 0,454 ± 0,034 | 0,575 ± 0,022 | 0,513 ± 0,040 | 0,572 ± 0,034 |
| Universitas Negeri Amerika | 0,576 ± 0,028 | 0,565 ± 0,023 | 0,577 ± 0,034 | 0,557 ± 0,033 | 0,530 ± 0,032 | 0,553 ± 0,028 | 0,541 ± 0,040 | 0,590 ± 0,033 |
| Bapak/Ibu | 0,573 ± 0,027 | 0,566 ± 0,022 | 0,586 ± 0,032 | 0,558 ± 0,033 | 0,540 ± 0,031 | 0,554 ± 0,026 | 0,545 ± 0,034 | 0,595 ± 0,040 |
| uji t | 0,572 ± 0,032 | 0,568 ± 0,020 | 0,579 ± 0,035 | 0,562 ± 0,030 | 0,537 ± 0,029 | 0,555 ± 0,024 | 0,535 ± 0,038 | 0,594 ± 0,035 |
| WRST | 0,596 ± 0,031 | 0,577 ± 0,025 | 0,588 ± 0,041 | 0,574 ± 0,036 | 0,532 ± 0,038 | 0,587 ± 0,028 | 0,548 ± 0,036 | 0,605 ± 0,034 |
| saya | 0,594 ± 0,025 | 0,528 ± 0,032 | 0,567 ± 0,039 | 0,615 ± 0,027 | 0,467 ± 0,036 | 0,591 ± 0,024 | 0,531 ± 0,041 | 0,586 ± 0,037 |
Catatan: Nilai yang dicetak tebal mewakili AUC dan deviasi standar dari kombinasi model yang optimal.
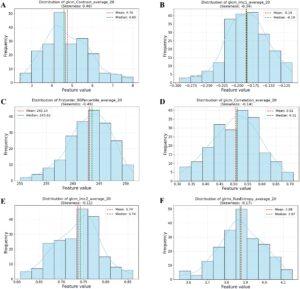
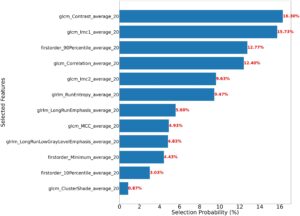
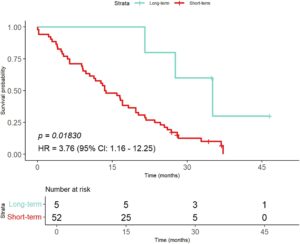
Enam fitur teratas dan distribusinya dari kombinasi model MI-KNN di Bagian 2.8 diilustrasikan dalam Gambar 2. Enam fitur mendekati distribusi normal. Distribusi normal menunjukkan bahwa fitur-fitur ini relatif stabil dalam pasien, yang mencerminkan variabilitas antarindividu yang terbatas. Fitur-fitur yang ditunjukkan dalam Gambar 3 digunakan untuk menganalisis kontribusi dari 12 fitur teratas yang dipilih pada kombinasi model MI-KNN. Dua fitur teratas, glcm_Contrast_average_20 dan glcm_Imc1_average_20, dianggap paling relevan dengan hasil pasien karena frekuensi pemilihannya yang tertinggi, yang menggarisbawahi potensinya sebagai biomarker untuk prediksi kelangsungan hidup GBM. Akhirnya, dalam analisis kelangsungan hidup kohort validasi eksternal, pasien kelangsungan hidup jangka panjang menunjukkan probabilitas kelangsungan hidup yang lebih tinggi dibandingkan dengan pasien kelangsungan hidup jangka pendek, dengan perbedaan yang signifikan secara statistik antara kedua kelompok (Gambar 4 ), yang menunjukkan bahwa model klasifikasi yang dibangun memiliki nilai prediktif yang signifikan untuk titik akhir kelangsungan hidup pada pasien GBM. Berdasarkan enam fitur teratas dari kombinasi model MI-KNN dalam kelompok pelatihan, pengklasifikasi KNN dilatih. Dalam kelompok validasi eksternal, kinerja klasifikasi diamati dengan AUC sebesar 0,594, ACC sebesar 0,754, dan skor F1 sebesar 0,848.