ABSTRAK
Model kemometrik memainkan peran penting dalam analisis spektroskopi makanan, khususnya dengan spektroskopi inframerah dekat (NIRS), yang memungkinkan prediksi dan pemantauan sifat fisikokimia yang akurat. Meskipun metode kemometrik telah terbukti menjadi alat yang berguna dalam analisis NIRS, keandalannya bergantung pada validasi yang ketat untuk memastikan ketelitian prediksi dan penerapannya. Tinjauan sistematis ini meneliti strategi validasi yang diterapkan pada model regresi dalam analisis makanan berbasis NIRS, dengan menekankan penggunaan validasi silang, validasi eksternal, dan angka prestasi (FoM) sebagai alat evaluasi utama. Pencarian literatur yang komprehensif ini mengidentifikasi tren dalam metodologi validasi, menyoroti ketergantungan yang sering terjadi pada regresi partial least squares (PLS) dan kelemahan umum dalam metodologi validasi dan pelaporannya. Meskipun validasi eksternal dianggap sebagai pendekatan terbaik, banyak penelitian tidak memilikinya dan hanya menggunakan metode validasi silang, yang dapat menyebabkan estimasi kinerja model yang terlalu optimis. Lebih jauh, ketidakkonsistenan dalam pemilihan dan definisi FoM menghalangi perbandingan langsung antar penelitian. Tinjauan ini menggarisbawahi perlunya peningkatan transparansi metodologi dan ketelitian dalam validasi model kemometrik untuk meningkatkan keandalannya.
1 Pendahuluan
Model kemometrik telah menjadi alat yang sangat diperlukan dalam kimia analitik modern, yang memungkinkan ekstraksi dan transformasi kumpulan data kompleks menjadi informasi yang bermakna yang dihasilkan oleh teknik spektroskopi tingkat lanjut [ 1 ]. Dalam bidang analisis pangan, model-model ini digunakan secara luas untuk memprediksi sifat fisikokimia utama, memantau kualitas, dan memastikan kepatuhan terhadap peraturan keselamatan [ 2 ]. Di antara berbagai pendekatan kemometrik, model regresi sangat menonjol karena kemampuannya untuk membangun hubungan kuantitatif antara data spektral dan pengukuran referensi [ 3 ]. Model-model ini telah menemukan aplikasi yang luas bersama dengan spektroskopi inframerah dekat (NIR), sebuah teknik yang umum digunakan dalam ilmu pangan karena sifatnya yang cepat dan tidak merusak serta kemampuannya untuk menganalisis beberapa komponen secara bersamaan. Integrasi spektroskopi inframerah dekat (NIRS) dengan model kemometrik telah menghasilkan kemajuan signifikan dalam pengendalian kualitas dan pemantauan proses. Perkembangan ini telah dengan tegas menetapkan NIRS sebagai komponen fundamental dari analisis pangan [ 4 , 5 ].
NIRS bergantung pada penyerapan cahaya di wilayah NIR, menangkap nada tambahan dan kombinasi mode getaran fundamental ikatan molekuler. Data spektral ini secara inheren multivariat, yang mengandung banyak informasi tentang komposisi molekuler sampel makanan. Namun, kompleksitas dan dimensionalitas tinggi spektrum NIR memerlukan penggunaan teknik kemometrik untuk mengekstrak informasi yang relevan. Model regresi sangat berharga dalam konteks ini, karena memungkinkan penentuan kuantitatif atribut makanan penting, seperti kadar air, protein, lemak, dan konsentrasi kontaminan [ 6 ].
Namun, ketelitian model regresi kemometrik tunduk pada validasi yang ketat. Validasi adalah proses menilai kemampuan model untuk bekerja dengan kuat pada data baru yang tidak terlihat, sehingga memastikan generalisasi dan kemampuan prediktifnya di luar kumpulan data kalibrasi [ 7 ]. Ini sangat penting dalam analisis makanan, di mana prediksi model secara langsung memengaruhi keputusan yang terkait dengan kualitas produksi, kepatuhan terhadap peraturan, dan keselamatan konsumen. Validasi model yang tidak memadai dapat menyebabkan overfitting data kalibrasi, sehingga menghasilkan estimasi kinerja yang terlalu optimis ketika diterapkan pada kondisi dunia nyata. Kegagalan tersebut dapat memiliki implikasi yang signifikan, termasuk kerugian ekonomi, penarikan kembali produk, dan keamanan pangan yang terganggu [ 8 ].
Dalam konteks NIRS dan pemodelan regresi, validasi harus memperhitungkan tantangan yang ditimbulkan oleh data spektral. Spektrum NIR sering kali dicirikan oleh kolinearitas tinggi di antara variabel, variabilitas karena heterogenitas sampel, dan noise yang disebabkan oleh instrumentasi atau kondisi lingkungan [ 6 ]. Akibatnya, strategi validasi yang kuat sangat penting untuk memastikan keandalan dan penerapan model kemometrik. Validasi eksternal, di mana kumpulan data independen digunakan untuk menilai kinerja dan generalisasi model, dianggap sebagai standar emas. Namun, karena kendala praktis, seperti ketersediaan data yang terbatas, teknik validasi internal seperti validasi silang (CV), yang membagi set kalibrasi menjadi subset pelatihan dan pengujian, sering kali diperlukan untuk optimasi hiperparameter model, seperti metode praproses data atau dimensionalitas model [ 9 ]. Selain itu, penilaian metode analitis ini didasarkan pada penggunaan angka prestasi kuantitatif (FoM), indikator kinerja utama yang memberikan wawasan tentang akurasi prediktif, kekokohan, dan penerapan praktis model. Metrik ini memungkinkan peneliti untuk mengevaluasi pendekatan validasi yang berbeda secara sistematis, menyempurnakan model mereka dan meningkatkan keandalannya untuk aplikasi dunia nyata dalam analisis pangan [ 10 ].
Secara keseluruhan, tinjauan sistematis ini difokuskan pada studi validasi model regresi kemometrik yang diterapkan pada NIRS dalam analisis pangan yang dapat ditemukan dalam literatur. Ketergantungan yang semakin besar pada model-model ini menggarisbawahi perlunya praktik validasi yang ketat dan ilmiah. Dengan memeriksa metodologi terkini, menyoroti praktik terbaik, dan menggarisbawahi praktik yang kurang efektif, tinjauan ini ditujukan untuk berkontribusi pada kemajuan metodologi validasi kemometrik yang ketat. Validasi yang kuat merupakan langkah metodologis penting dalam memastikan bahwa metode analitis berdasarkan spektroskopi dan kemometrik mencapai potensi penuhnya dalam meningkatkan kualitas, keamanan, dan efisiensi produksi dan analisis pangan.
2 Latar Belakang Teoritis
2.1 Model Regresi Multivariat
Model regresi multivariat adalah kelas teknik statistik yang digunakan untuk menganalisis dan memprediksi hubungan antara beberapa variabel independen ( X ) dan satu atau lebih variabel dependen ( y ) [ 3 ]. Metode yang paling umum untuk melakukannya adalah model linier; model ini memperluas regresi linier sederhana dengan mempertimbangkan beberapa prediktor, yang memungkinkan evaluasi simultan terhadap efeknya pada variabel respons. Dalam bentuk dasarnya, model linier mengasumsikan bahwa hubungan antara prediktor dan respons bersifat linier dan dapat dinyatakan secara matematis dengan Persamaan ( 1 ):
![]()
di mana β adalah vektor koefisien regresi dan ε memperhitungkan residual. Dalam perluasan regresi linier kuadrat terkecil univariat seperti regresi linier multivariat atau berganda (MLR), regresi komponen utama (PCR) dan kuadrat terkecil parsial (PLS), koefisien diestimasi dengan meminimalkan jumlah kuadrat residual. Ini memberikan estimasi linier tak bias terbaik, yang berarti bahwa di bawah asumsi normalitas, homoskedastisitas dan independensi kesalahan, koefisien yang diestimasi memiliki varians terendah di antara semua estimator linier dan, rata-rata, sama dengan nilai parameter sebenarnya tanpa estimasi lebih atau kurang sistematis. Model-model ini umumnya digunakan di berbagai bidang karena fleksibilitasnya dalam menangani data kompleks dan interpretabilitasnya dalam mengidentifikasi kontribusi setiap prediktor [ 5 , 11 ].
Selain model linear, teknik yang lebih kompleks tetapi fleksibel telah dikembangkan untuk mengatasi keterbatasan seperti nonlinier. Pendekatan ini dapat dikategorikan secara luas berdasarkan metodologinya. Metode berbasis kernel, seperti support vector machines (SVMs) [ 12 ] dan kernel partial least squares (KPLS) [ 13 ], memetakan data ke dalam ruang berdimensi lebih tinggi menggunakan fungsi kernel untuk berpotensi menangkap hubungan nonlinier. Metode aproksimasi nonlinier lainnya, termasuk jaringan saraf tiruan (ANNs) [ 14 ], memodelkan dependensi kompleks melalui penggunaan satu atau lebih lapisan node, yang juga disebut neuron. Secara khusus, extreme learning machines (ELM) menggunakan satu lapisan neuron yang diberi bobot acak dan mengkalibrasi bobot node keluaran [ 15 ]. Dengan cara yang agak mirip, teknik pembelajaran ensemble nonparametrik, seperti random forest (RFs) dan gradient boosting, menangkap nonlinieritas dan interaksi variabel dengan menggabungkan prediksi dari beberapa pohon keputusan [ 16 ]. Sebaliknya, analisis data komposisi (CoDa) disesuaikan untuk kumpulan data dengan variabel sebagai proporsi, umum dalam ilmu pangan dan lingkungan, menggunakan transformasi untuk menangani sifat terbatasnya [ 17 ]. Metode-metode ini membentuk perangkat kemometrik yang komprehensif, yang memungkinkan pemodelan sistem yang lebih kompleks di luar cakupan pendekatan linier murni.
Berbeda dengan pendekatan univariat, model regresi multivariat dapat menangkap efek gabungan dari beberapa prediktor, sehingga membuatnya sangat berguna untuk sistem dengan interaksi kompleks seperti dalam spektroskopi. Namun, efektivitas model ini bergantung pada kemampuannya untuk memperhitungkan multikolinearitas, mengurangi dimensionalitas jika perlu, dan memastikan ketahanan prediktif melalui validasi yang ketat [ 18 ].
2.2 Validasi Eksternal
Validasi eksternal adalah proses mengevaluasi model prediktif menggunakan kumpulan data independen yang tidak terlibat dalam pengembangan atau kalibrasi model. Kumpulan validasi eksternal adalah komponen fundamental dari evaluasi model yang ketat dalam kemometrika, yang menyediakan ukuran yang independen dan tidak bias atas kemampuan generalisasi dan kinerja suatu model. Dengan memanfaatkan kumpulan data yang sepenuhnya terpisah dari proses kalibrasi, validasi eksternal memastikan bahwa penilaian kinerja model mencerminkan kapasitasnya untuk memprediksi data yang tidak terlihat dalam kondisi yang realistis. Dalam domain seperti spektroskopi dan analisis makanan, di mana model sering kali menghadapi matriks sampel yang kompleks dan bervariasi, validasi eksternal berfungsi sebagai standar emas untuk mengevaluasi kinerja prediktif, mengidentifikasi overfitting, dan secara keseluruhan memvalidasi keandalan model kemometrika [ 9 ]. Pemilihan strategi validasi eksternal dapat dilakukan dengan metodologi yang berbeda, yang dibahas dalam subbagian berikut, dengan mempertimbangkan bahwa metodologi tersebut berbeda dalam cara memilih kumpulan validasi, seperti yang diilustrasikan dalam Gambar 1 .

2.2.1 Set Independen
Menggunakan kumpulan data independen untuk validasi merupakan pendekatan paling ketat untuk memvalidasi model. Tidak seperti pemisahan data atau metode validasi internal, kumpulan data validasi independen dibuat secara terpisah dari data yang digunakan untuk pelatihan dan pengoptimalan model, dengan sampel yang benar-benar tak terlihat yang mencakup domain yang dimaksud untuk model yang diusulkan. Hal ini memastikan bahwa proses evaluasi mencerminkan kemampuan model untuk beradaptasi dengan domain pekerjaan, bebas dari bias atau overfitting yang diperkenalkan selama kalibrasi, termasuk praproses data dan pemilihan hiperparameter. Pendekatan ini memberikan ukuran yang lebih objektif dari kemampuan prediktif dan utilitas praktisnya, menjadikannya praktik yang direkomendasikan dalam pengembangan model kemometrik [ 9 ].
2.2.2 Pemisahan Acak
Bahasa Indonesia: Ketika ketersediaan set validasi independen terbatas atau tidak layak, pemisahan set kalibrasi menjadi subset pelatihan dan validasi menjadi alternatif praktis untuk menilai kinerja model. Dalam pendekatan ini, data kalibrasi dibagi menjadi dua bagian: satu subset digunakan untuk melatih model, sementara yang lain dicadangkan untuk memvalidasi model, dalam proporsi yang dipilih oleh analis. Meskipun tidak seketat menggunakan set validasi yang sepenuhnya independen, pemisahan set kalibrasi menyediakan mekanisme untuk memperkirakan validasi eksternal, terutama dalam skenario dengan data terbatas. Namun, harus dipastikan bahwa set validasi yang digunakan mewakili domain kerja yang dimaksudkan untuk model dalam hal variabilitas [ 7 , 9 ].
Pemisahan acak adalah metode langsung untuk mempartisi dataset menjadi subset kalibrasi dan validasi dengan menetapkan sampel secara acak ke setiap kelompok. Pendekatan ini digunakan secara luas karena kesederhanaan dan efisiensi komputasinya, karena tidak memerlukan algoritma yang rumit atau asumsi tambahan. Namun, pendekatan ini memiliki keterbatasan yang nyata, terutama ketika diterapkan pada dataset yang kecil atau tidak seimbang. Pemisahan acak tidak memastikan bahwa subset tersebut mewakili keseluruhan distribusi data, yang dapat menghasilkan set kalibrasi atau validasi yang tidak memiliki variabilitas kritis atau gagal mencakup seluruh ruang fitur. Akibatnya, hal ini dapat menyebabkan estimasi kinerja model yang bias atau tidak dapat diandalkan, misalnya ketika replikasi atau sampel yang entah bagaimana terkait ada dalam dataset [ 9 , 19 ]. Sementara pemisahan acak mungkin cocok untuk dataset besar dengan sampel yang seimbang, independen, dan beragam, kehati-hatian harus dilakukan untuk memastikan bahwa subset secara akurat mencerminkan variabilitas yang ada dalam dataset lengkap, yang sering kali membutuhkan strategi tambahan seperti stratifikasi untuk mengatasi potensi bias [ 20 , 21 ].
2.2.3 Algoritma Kennard–Stone
Algoritma Kennard–Stone adalah metode sistematis untuk memilih subset representatif dari suatu dataset untuk memastikan cakupan yang seragam dari ruang variabel input. Awalnya, ia mengidentifikasi dua sampel yang paling jauh terpisah dalam ruang variabel untuk memaksimalkan keragaman. Selanjutnya, ia secara berulang memilih sampel yang paling jauh dari yang sudah dipilih, memastikan setiap sampel baru menambahkan informasi maksimum tentang wilayah yang belum dieksplorasi, yang memaksimalkan variabilitas dataset [ 22 ]. Pemisahan ini dapat dilakukan dengan menggunakan jarak Euclidean atau menggunakan jarak Mahalanobis, yaitu jarak berskala varians, untuk representasi ruang yang lebih baik [ 23 ].
2.2.4 Algoritma SPXY
Algoritma SPXY (sample set partitioning based on joint X – y distances) merupakan penyempurnaan dari metode Kennard–Stone. Tidak seperti Kennard–Stone, SPXY menggabungkan variabilitas dalam ruang prediktor ( X ) dan respons ( y ). Dengan menormalkan dan menggabungkan jarak dalam X dan y , SPXY memastikan bahwa subset kalibrasi dan validasi tidak hanya mewakili ruang prediktor tetapi juga memperhitungkan keberagaman dalam nilai respons. Pertimbangan bersama ini meningkatkan ketahanan dan kemampuan prediktif model dengan mencegah ekstrapolasi dan menyelaraskan pemilihan sampel dengan variabilitas fitur yang diprediksi dengan lebih baik. Hasilnya, SPXY berharga dalam aplikasi di mana fitur yang akan diprediksi tidak terkait dengan sumber utama varians dalam sinyal analitis, yang sering terjadi saat makanan dianalisis dengan NIRS [ 24 ].
2.2.5 Algoritma Bawang
Algoritma Onion adalah metode untuk membagi dataset menjadi set kalibrasi dan validasi berdasarkan jaraknya dari pusat dataset di ruang fitur. Algoritma mengatur sampel dalam lapisan konsentris ‘bawang’, dengan setiap lapisan disertakan dalam set kalibrasi atau validasi, secara bergantian. Biasanya, sampel terluar, yang mewakili ekstrem dari distribusi data, dipilih untuk set kalibrasi, memastikan bahwa set kalibrasi mencakup sampel yang paling beragam dan ekstrem, sehingga menangkap variabilitas dalam ruang fitur. Pemisahan bawang meminimalkan risiko ekstrapolasi selama validasi dengan memastikan bahwa set validasi terletak di dalam ruang yang dicakup oleh set kalibrasi. Metode ini sangat relevan dalam analisis multivariat, di mana cakupan ruang data yang seragam penting untuk membangun model yang kuat dan dapat digeneralisasi [ 25 ].
2.2.6 Pemisahan Terstruktur atau Kustom
Ketika dataset diatur oleh kelompok sampel berdasarkan struktur hierarkis, seperti replikasi, efek batch atau lokasi pengambilan sampel, pemisahan terstruktur dapat memastikan bahwa subset yang digunakan untuk kalibrasi dan validasi mempertahankan hubungan yang melekat dalam data. Tidak seperti pemisahan acak, yang dapat membagi sampel terkait secara sembarangan, pemisahan terstruktur memastikan bahwa seluruh kelompok sampel terkait disertakan atau dikecualikan bersama-sama dalam setiap subset. Pendekatan ini menjaga integritas variabilitas dataset dan mencegah kebocoran informasi, yang dapat menyebabkan estimasi kinerja model yang terlalu optimis [ 9 ].
Bahkan ketika struktur tersebut tidak ada, analis dapat memutuskan untuk secara sengaja menyertakan atau mengecualikan sampel tertentu dari set validasi menggunakan kriteria lain, seperti mempertahankan rentang atau distribusi nilai referensi dan menggunakan sampel atau pengukuran yang sangat menarik. Ini menciptakan subset validasi khusus dengan properti yang diinginkan.
2.2.7 Metode Pemisahan Lainnya
Lebih banyak metode pemisahan dataset juga telah diusulkan dalam literatur, misalnya, variasi dan ekstensi dari algoritma SPXY, seperti SPXY tertimbang [ 26 ] atau SPXY berbasis kernel [ 27 ]. Selain itu, metode lain yang didasarkan pada kuantifikasi relevansi setiap sampel untuk membangun model termasuk satu berdasarkan desain eksperimen D-optimal [ 28 ], yang lain berdasarkan sinyal analitis gabungan [ 29 ] atau yang lain berdasarkan leverage multivariat (LVG) [ 30 ]. Metode lain mengusulkan pemisahan data berdasarkan perbedaan sampel, seperti metode OptiSim [ 31 ], dan, misalnya, algoritma SPlit [ 32 ], yang mencoba menemukan skenario terburuk untuk validasi berdasarkan tetangga terdekat. Masing-masing dari mereka menawarkan kelebihannya dan mencoba menawarkan fokus baru pada validasi eksternal model kemometrik.
2.3 Strategi CV atau Resampling
Strategi validasi berdasarkan partisi set data kalibrasi sering digunakan untuk mengoptimalkan hiperparameter model dan memperkirakan kekokohannya, meskipun set data terpisah juga dapat digunakan. Strategi CV melibatkan partisi set data kalibrasi secara sistematis menjadi subset komplementer: semua kecuali satu subset digunakan untuk melatih model, dan subset yang tersisa digunakan untuk mengujinya. Proses ini diulang hingga semua sampel diprediksi untuk mendapatkan estimasi kinerja prediktif. Metode resampling, di sisi lain, menghasilkan beberapa set data baru dengan mengambil sampel secara acak (dengan atau tanpa penggantian) dari data asli. Set data baru ini digunakan untuk menyesuaikan kembali model secara berulang dan menilai variabilitas dalam parameter model dan metrik kinerja. Sementara metode resampling tidak selalu secara langsung memberikan estimasi kinerja prediktif dengan cara yang sama seperti CV, metode tersebut berharga untuk memperkirakan ketidakpastian dan stabilitas parameter model, terkadang menetapkan interval kepercayaan. Pilihan metode mana yang akan digunakan bergantung pada ukuran set data, kompleksitas, dan keberadaan sampel yang dikelompokkan atau terkait [ 9 ]. Setiap metodologi disajikan dalam subbagian berikut dan diilustrasikan dalam Gambar 2 .
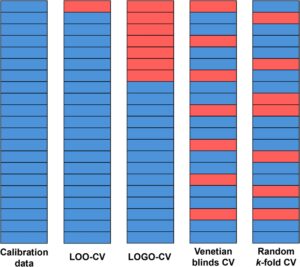
2.3.1 Validasi Silang Keluar-Satu-Keluar (LOO-CV)
Dalam LOO-CV atau CV penuh, kumpulan data dibagi sedemikian rupa sehingga setiap sampel digunakan sekali sebagai set validasi sementara sampel yang tersisa digunakan untuk melatih model. Proses ini diulang untuk setiap sampel dalam kumpulan data, menghasilkan iterasi sebanyak jumlah sampel, yang membuat algoritma ini intensif secara komputasi. Metode CV ini berguna untuk mengevaluasi efek sampel individual; namun, cenderung terlalu optimis untuk mengevaluasi kinerja model, khususnya dalam kumpulan data tempat sampel dengan korelasi tinggi di antara mereka hadir, seperti yang ditemukan dalam NIRS pangan [ 9 ].
2.3.2 Validasi Silang Keluar-Satu-Kelompok (LOGO-CV)
LOGO-CV, leave-one-patient-out cross-validation (LOPO-CV), custom subsets atau contiguous blocks CV adalah variasi dari CV yang dirancang untuk dataset dengan struktur berkelompok atau hierarkis, di mana sampel disusun ke dalam kelompok-kelompok berbeda berdasarkan karakteristik bersama, seperti replikasi, batch atau lokasi pengambilan sampel. Dalam LOGO-CV, seluruh kelompok ditinggalkan sebagai set validasi selama setiap iterasi, sementara kelompok yang tersisa digunakan untuk melatih model. Pendekatan ini memastikan bahwa set validasi independen dari data pelatihan dan mempertahankan hubungan yang melekat dalam kelompok, membuatnya sangat cocok untuk mengevaluasi variabilitas antar sampel dalam dataset dengan variabilitas bersarang atau hierarkis [ 9 ].
2.3.3 Tirai Venesia CV
Venetian blinds CV adalah metode partisi data untuk validasi model dengan membagi dataset menjadi subset yang berjarak sama dan tidak tumpang tindih, menyerupai pola bergantian dari venetian blind. Setiap subset atau lipatan digunakan sebagai set validasi satu kali, sedangkan subset yang tersisa digunakan untuk melatih model. Pendekatan ini memastikan bahwa sampel dari seluruh dataset disertakan dalam pelatihan dan validasi, yang sangat berguna untuk dataset dengan variabilitas terstruktur atau berurutan waktu. Metode ini efisien secara komputasi dan sangat cocok untuk dataset dengan titik data yang terdistribusi secara merata, tetapi mungkin tidak bekerja secara efektif dalam dataset dengan korelasi atau pengelompokan [ 9 ].
2.3.4 Subset Acak atau CV Lipatan k Acak
Random subsets atau random k -fold CV adalah metode di mana dataset dibagi secara acak menjadi k subset atau fold berukuran sama, dan model dilatih dan divalidasi sebanyak k kali. Dalam setiap iterasi, satu subset digunakan sebagai set validasi, sedangkan k -1 subset yang tersisa membentuk set pelatihan. Proses ini diulang hingga setiap subset berfungsi sebagai set validasi satu kali. Ketika prediksi untuk semua sampel individu tersedia, metrik kinerja dihitung, memberikan estimasi kinerja model yang kuat. Pendekatan ini banyak digunakan karena kesederhanaan dan fleksibilitasnya, terutama untuk dataset tanpa struktur atau pengelompokan yang melekat [ 9 ].
2.3.5 Metode Resampling
Strategi resampling berbeda dari teknik CV lainnya dengan berfokus pada pengambilan sampel acak berulang dari dataset untuk menghitung metrik validasi di setiap iterasi dan menggabungkannya, menyediakan metrik yang mencerminkan ketahanan dan stabilitas model [ 9 ].
Validasi bootstrap adalah metode resampling yang membuat beberapa subset data dengan mengambil sampel secara acak dengan penggantian dari dataset asli. Setiap sampel bootstrap atau iterasi biasanya memiliki ukuran yang sama dengan dataset asli tetapi dapat menyertakan sampel berulang sambil mengabaikan beberapa sampel. Model dilatih pada setiap sampel bootstrap dan diuji pada sampel yang tidak disertakan (sampel ‘out-of-bag’), yang memberikan estimasi kinerja model [ 33 , 34 ].
Validasi Monte Carlo melibatkan pembuatan beberapa pemisahan acak dari kumpulan data menjadi subset kalibrasi dan validasi. Dalam setiap iterasi, model dilatih pada subset kalibrasi dan diuji pada subset validasi, dan proses ini diulang berkali-kali dengan pemisahan acak yang berbeda. Pendekatan ini memberikan penilaian komprehensif terhadap kinerja model di berbagai partisi data potensial, menangkap variabilitas dalam metrik kinerja karena komposisi kumpulan data yang berbeda [ 35 ].
Metode jackknife adalah teknik resampling sistematis di mana satu sampel dikeluarkan dari kumpulan data pada satu waktu, dan model dilatih pada data yang tersisa. Proses ini diulang hingga setiap sampel dikeluarkan dari proses kalibrasi satu kali. Dengan menggabungkan hasil di semua iterasi, jackknife dapat memberikan estimasi variabilitas, ketidakpastian atau stabilitas dalam parameter model seperti koefisien regresi atau dimensionalitas, khususnya berguna untuk mendeteksi sampel atau outlier berpengaruh yang mungkin memengaruhi model secara tidak proporsional [ 34 ].
2.3.6 Metode Berbasis Permutasi
Metode berbasis permutasi dapat digunakan untuk menilai signifikansi statistik model kemometrik dengan membandingkan kinerjanya dengan model yang dibangun di atas variabel respons yang diubah secara acak. Meskipun metode ini tidak secara langsung memberikan evaluasi kinerja dalam hal kemampuan prediktif, metode ini dapat membantu dalam proses optimasi hiperparameter model dengan membedakan antara pengaturan parameter yang mengarah ke model yang menangkap struktur sebenarnya dalam data dan yang hanya sesuai dengan derau acak. Dengan mengubah variabel respons secara berulang dan menghitung ulang metrik model (seperti varians yang dijelaskan), adalah mungkin untuk membangun distribusi nol yang dapat dibandingkan dengan yang diamati. Dengan demikian, set hiperparameter yang secara konsisten menghasilkan model yang lebih baik daripada padanan yang diubah dapat dipilih dengan keyakinan yang lebih besar. Metode ini menjadi sangat berguna ketika berhadapan dengan kumpulan data kecil atau model dengan kompleksitas tinggi dan risiko overfitting [ 20 , 36 ].
2.3.7 Metode CV Lainnya
Procrustes CV adalah metode baru yang menjembatani CV k- fold acak dan validasi set uji independen dalam pemodelan kemometrik. Metode ini menghasilkan ‘set pseudovalidasi’ dengan menggabungkan ketidakpastian pengambilan sampel dari CV ke dalam data kalibrasi, yang mensimulasikan set uji independen. Tidak seperti CV konvensional, Procrustes CV memungkinkan penilaian parameter model global, seperti varians dan residual yang dijelaskan, dan sangat efektif dalam mendeteksi overfitting. Meskipun bukan pengganti validasi independen, metode CV ini menawarkan alternatif yang kuat untuk pengoptimalan dan eksplorasi model [ 37 ].
Validasi silang ganda berulang (RDCV) adalah teknik yang menggabungkan CV internal untuk pemilihan model dengan validasi eksternal untuk estimasi kinerja yang tidak bias. Proses ini terdiri dari dua loop CV bersarang: loop luar, yang membagi kumpulan data menjadi subset pelatihan dan validasi untuk mengevaluasi kinerja model akhir, dan loop dalam, yang digunakan untuk pemilihan model dan penyetelan hiperparameter. Struktur ini memastikan bahwa pengoptimalan hiperparameter tidak memengaruhi estimasi kinerja akhir, mengurangi risiko overfitting, terutama dalam kumpulan data kecil [ 38 ].
CV Probabilistik [ 39 ] dan CV Bayesian [ 40 ] adalah variasi lain dari metode CV, yang dirancang untuk mengatasi keterbatasan evaluasi model deterministik dengan memperkenalkan elemen probabilistik ke dalam proses validasi. Tidak seperti CV standar, yang mengevaluasi kinerja model melalui partisi data tetap, metode ini menggabungkan ketidakpastian ke dalam prosedur validasi, memodelkan kesalahan prediksi sebagai fungsi probabilistik. Pendekatan ini membagi kumpulan data menjadi beberapa bagian dan menggunakan kerangka kerja probabilistik, seperti distribusi Gaussian, untuk memperkirakan kinerja model.
2.4 Angka Keunggulan
FoM adalah alat penting untuk mengevaluasi kinerja metode analitis. Metrik ini memberikan penilaian kuantitatif terhadap kinerja dan ketahanan model, termasuk kualitas prediksi, keandalan pengukuran, dan kemampuan untuk menggeneralisasi di berbagai kumpulan data [ 10 ]. Metrik kesalahan seperti root mean square error (RMSE), mean absolute error (MAE), standard error (SE), relative error (RE), dan mean square error (MSE) banyak digunakan untuk mengukur kesalahan prediksi. RMSE memberikan penalti yang lebih berat terhadap kesalahan yang lebih besar, sementara MAE memberikan ukuran kesalahan rata-rata yang lebih sederhana, kurang sensitif terhadap outlier. SE menangkap variabilitas di sekitar mean, dan MSE mengevaluasi perbedaan kuadrat antara nilai yang diamati dan diprediksi, yang menekankan deviasi yang lebih besar [ 41 ].
Metrik korelasi dan kecocokan memberikan wawasan mengenai hubungan antara nilai yang diamati dan diprediksi. Koefisien korelasi ( R ) dan koefisien determinasi ( R 2 ) mengukur kekuatan dan arah hubungan linier; yang terakhir juga setara dengan varians yang dijelaskan oleh model (EV) [ 42 ]. Koefisien korelasi konkordansi (CCC) mengevaluasi kesepakatan dengan menggabungkan ukuran presisi dan akurasi [ 43 ].
Karakteristik regresi lainnya antara data yang diprediksi dengan data yang diamati, termasuk kemiringan, offset, dan bias, memberikan informasi tambahan tentang penyimpangan sistematis dalam prediksi. Kemiringan yang mendekati satu dan offset yang mendekati nol menunjukkan model yang tidak bias. Selain itu, uji statistik seperti uji permutasi menilai signifikansi hubungan yang diamati, memastikan hasil model bermakna dan bukan karena kebetulan [ 8 ].
Rasio kinerja mengevaluasi kemampuan prediktif model dengan cara yang terstandarisasi, sehingga nilai-nilai seperti rasio kinerja terhadap deviasi (RPD) dan rasio kesalahan rentang (RER) dapat dibandingkan antar model. RPD menstandardisasi RMSE atau metrik kesalahan lainnya, membandingkannya dengan deviasi standar observasi, dengan nilai yang lebih tinggi menunjukkan kinerja yang lebih baik, sementara RER mempertimbangkan rentang data relatif terhadap RMSE [ 42 ]. Metrik lainnya, seperti rasio kinerja terhadap jarak interkuartil (RPIQ), meningkatkan ketahanan dengan menggunakan rentang interkuartil alih-alih deviasi standar, sehingga membuatnya kurang sensitif terhadap outlier [ 44 ].
Selain itu, properti model lainnya seperti batas deteksi (LOD) dan batas kuantifikasi (LOQ) sangat penting dalam aplikasi analitis, menentukan jumlah analit terkecil yang dapat dideteksi atau dikuantifikasi dengan andal, masing-masing [ 45 ]. Metrik lain yang kurang dikenal, seperti deteksi kapasitas (CCβ), mengidentifikasi jumlah analit terkecil yang dapat dideteksi dengan negatif palsu minimal [ 17 , 46 ]. Secara keseluruhan, FoM ini menyediakan kerangka kerja yang komprehensif untuk mengevaluasi dan membandingkan model kemometrik, memastikan keandalan dan penerapannya dalam berbagai skenario.
Namun, perlu dicatat bahwa terdapat lebih dari satu definisi untuk beberapa FoM, seperti RMSE, LOD atau bias. Oleh karena itu, alih-alih menawarkan definisi matematika di sini, kami merujuk pembaca ke publikasi referensi lain dalam topik tersebut [ 10 , 45 , 47 – 49 ].
3 Metodologi
3.1 Pencarian Sistematis
Metode penelitian untuk tinjauan sistematis mengikuti pedoman PRISMA (Gambar 3 ), yang memastikan transparansi dan keandalan dalam tinjauan sistematis dengan mematuhi daftar periksa terstruktur [ 50 ]. Kriteria kelayakan difokuskan pada studi yang membahas penggunaan NIRS untuk analisis pangan, khususnya menargetkan strategi validasi dalam pemodelan prediktif.
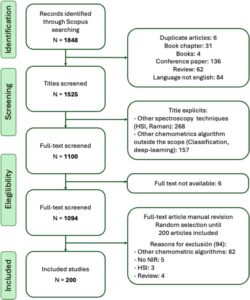
Sumber informasi utama untuk tinjauan ini adalah SCOPUS, tempat penelusuran dilakukan pada tanggal 4 Desember 2024. Strategi penelusuran menggunakan kueri berikut:
(JUDUL-ABS-KUNCI (“near-infrared” ATAU “near-infrared spectroscopy” ATAU “NIR” ATAU “NIR analysis”) DAN JUDUL-ABS-KUNCI (“food” ATAU “food quality” ATAU “food analysis” ATAU “food safety” ATAU “food composition” ATAU “food authentication” ATAU “food science”) DAN JUDUL-ABS-KUNCI (“PLS” ATAU “partial least squares” ATAU “PLS regression” ATAU “multivariate analysis” ATAU “chemometrics” ATAU “regression” ATAU “predictive modeling” ATAU “machine learning”)) DAN TAHUN PUBLIK > 2014 DAN TAHUN PUBLIK < 2026.
Strategi ini dirancang untuk menyertakan berbagai terminologi dan sinonim yang relevan dengan bidang tersebut sambil mengecualikan studi di luar cakupan tinjauan. Pilihan untuk menggunakan istilah pencarian yang luas seperti ‘makanan’ disengaja untuk menjaga inklusivitas di berbagai matriks makanan dan untuk memberikan gambaran umum tentang strategi validasi di lapangan. Pencarian dibatasi pada publikasi dari tahun 2015 hingga 2025, dipilih untuk mewakili strategi validasi terbaru dalam aplikasi NIR untuk analisis makanan. Kerangka waktu ini ditentukan oleh penulis, karena tidak ada konsensus yang ditetapkan tentang frekuensi yang tepat untuk tinjauan sistematis [ 51 ].
Sebanyak 1848 catatan awalnya diambil. Catatan-catatan ini disaring berdasarkan relevansi dan kualitas, yang mengarah pada pengecualian studi yang tidak berfokus pada penerapan NIR dalam analisis pangan. Artikel-artikel di luar cakupan, seperti artikel yang menganalisis metodologi nonprediksi atau tidak terkait, disingkirkan. Setelah penyaringan, 1094 catatan dimasukkan dalam tinjauan. Karena banyaknya artikel yang memenuhi kriteria inklusi setelah penyaringan, pemilihan acak sebanyak 200 artikel dilakukan untuk memastikan keterkelolaan.
Data diekstraksi secara sistematis ke dalam file Microsoft Excel, termasuk informasi tentang jurnal, tahun, strategi CV, strategi validasi eksternal, FoM yang digunakan, apakah persamaan FoM tersebut ditampilkan, algoritma yang digunakan, dan apakah grafik yang menunjukkan model disertakan.
3.2 Tanda Ketelitian Validasi
Untuk mengevaluasi ketelitian strategi validasi yang digunakan dalam studi yang dipublikasikan, kerangka kerja tanda ketelitian validasi dikembangkan. Kerangka kerja ini secara sistematis menilai studi berdasarkan penggunaan dan deskripsi metode CV dan validasi eksternal. Tanda ketelitian validasi mencakup sembilan kategori, yang diberi peringkat dari 1 ( paling tidak ketat ) hingga 9 ( paling ketat ), dengan kriteria yang berasal dari kombinasi keempat elemen ini: apakah studi menerapkan bentuk CV apa pun untuk memvalidasi temuannya, apakah studi memberikan informasi terperinci tentang metodologi CV (misalnya, jumlah lipatan, strategi pengacakan atau pemisahan data), apakah studi menggunakan validasi eksternal dengan menguji model atau hasilnya pada kumpulan data independen dan apakah metodologi untuk validasi eksternal dijelaskan secara cukup rinci (misalnya, asal kumpulan data, langkah-langkah praproses dan metrik evaluasi). Skor tertinggi (9) diberikan kepada studi yang menggunakan validasi CV dan eksternal dan memberikan deskripsi terperinci tentang metodologinya. Setiap artikel yang termasuk dalam tinjauan dievaluasi secara sistematis, dan informasi mengenai pendekatan validasinya diekstraksi. Setiap studi ditandai sebagai ‘YA’ atau ‘TIDAK’ untuk penggunaan CV atau validasi eksternal, dan jika salah satu atau keduanya digunakan, deskripsi strategi dievaluasi. Kemudian, skor diberikan berdasarkan hasil matriks penilaian yang ditunjukkan pada Tabel 1. Kombinasi kriteria tertentu secara logis dikecualikan. Misalnya, studi yang tidak menggunakan CV tidak dapat menentukan strategi CV, dan skenario tersebut dihilangkan dari desain penilaian faktorial
| Tanda ketelitian validasi | Penggunaan CV | Apakah strategi CV telah dideklarasikan? | Penggunaan validasi eksternal | Apakah strategi validasi eksternal dideklarasikan? |
|---|---|---|---|---|
| 1 | TIDAK | TIDAK | TIDAK | TIDAK |
| 2 | YA | TIDAK | TIDAK | TIDAK |
| 3 | YA | YA | TIDAK | TIDAK |
| 4 | TIDAK | TIDAK | YA | TIDAK |
| 5 | YA | TIDAK | YA | TIDAK |
| 6 | YA | YA | YA | TIDAK |
| 7 | TIDAK | TIDAK | YA | YA |
| 8 | YA | TIDAK | YA | YA |
| 9 | YA | YA | YA | YA |
Semua data diekstraksi dan dievaluasi secara independen oleh dua peninjau untuk memastikan objektivitas. Setiap perbedaan dalam penilaian diselesaikan melalui diskusi konsensus. Distribusi nilai ketelitian validasi di seluruh studi dianalisis untuk mengidentifikasi praktik validasi umum dan tren dalam ketelitian metodologis. Statistik deskriptif, termasuk distribusi frekuensi dan skor ketelitian validasi rata-rata, dihitung. Korelasi antara skor nilai ketelitian validasi dan karakteristik studi dinilai secara visual.
4 Hasil dan Pembahasan
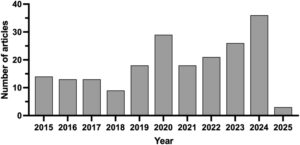
Artikel-artikel terpilih yang ditinjau dianalisis untuk memahami distribusi tahun dan kesetaraannya dengan seluruh set artikel. Distribusi temporal artikel-artikel yang ditinjau dari tahun 2015 hingga 2025, yang memiliki distribusi yang mirip dengan keseluruhan (data tidak ditampilkan), ditunjukkan pada Gambar 4. Jumlah publikasi tetap relatif stabil dari tahun 2015 hingga 2019. Peningkatan yang nyata diamati pada tahun 2020, mencapai puncak pertamanya, mungkin dipengaruhi oleh penguncian pandemi COVID-19 [ 52 ], diikuti oleh jumlah publikasi yang berfluktuasi namun secara konsisten lebih tinggi dari tahun ke tahun dari tahun 2021 hingga 2024. Jumlah artikel yang ditinjau tertinggi diterbitkan pada tahun 2024, yang menunjukkan minat penelitian yang semakin meningkat pada topik tersebut. Sebaliknya, sejumlah kecil artikel yang disertakan pada tahun 2025 kemungkinan mencerminkan pengumpulan data yang tidak lengkap untuk tahun itu pada saat tinjauan ini. Tren ini menunjukkan peningkatan fokus pada penerapan model regresi berbasis NIR untuk prediksi sifat makanan, terutama dalam beberapa tahun terakhir.
Jurnal-jurnal yang diulas mencakup beragam kategori Journal Citation Reports ( JCR ), yang mencerminkan sifat interdisipliner penelitian pada model regresi berbasis NIR dan prediksi sifat makanan. Jumlah jurnal tertinggi berada di bawah kategori ‘Food Science & Technology’ (29 jurnal), yang menggarisbawahi relevansi yang kuat dari bidang ini dengan analisis makanan. Kategori menonjol lainnya termasuk ‘Chemistry, Analytical’ (11 jurnal) dan ‘Chemistry, Applied’ (sembilan jurnal), yang menyoroti pentingnya metodologi kimia dalam penelitian makanan. Khususnya, kategori yang terkait dengan spektroskopi, instrumentasi dan pencitraan, seperti ‘Spectroscopy’ (lima jurnal), ‘Instruments & Instrumentation’ (empat jurnal) dan ‘Imaging Science & Photographic Technology’ (dua jurnal), menekankan peran penting teknik analisis tingkat lanjut di lapangan. Kategori lain, termasuk ‘Engineering’, ‘Remote Sensing’, ‘Artificial Intelligence’ dan ‘Statistics’, menunjukkan integrasi pendekatan komputasional, teknologi dan matematika dalam penelitian yang terkait dengan makanan. Secara keseluruhan, distribusi ini menyoroti sifat multidisiplin analisis pangan berbasis NIR, yang mencakup ilmu pangan, kimia, teknik, pertanian, dan metodologi berbasis data.
Mengingat berbagai macam disiplin ilmu yang terlibat dalam validasi model prediksi NIR, berbagai algoritma prediksi juga telah digunakan untuk mengembangkan model. Distribusi algoritma regresi yang digunakan dalam artikel yang ditinjau diilustrasikan dalam diagram lingkaran pada Gambar 5. Untuk 200 artikel yang ditinjau, PLS adalah algoritma regresi yang paling umum digunakan, menempati bagian terbesar dari diagram. Dominasi ini menggarisbawahi PLS sebagai metode yang lebih disukai untuk prediksi sifat makanan berbasis NIR, mungkin karena ketahanannya dalam menangani data spektral kolinear dan kinerjanya yang mapan dalam NIRS [ 53 ]. Algoritma regresi lainnya muncul jauh lebih jarang. Di antara ini, SVM dan MLR memiliki bagian yang relatif lebih besar dibandingkan dengan RF, PCR, ELM dan CoDa, yang hanya mencakup sebagian kecil dari total algoritma yang digunakan.
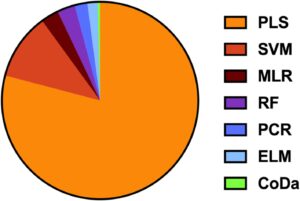
Tren ini menyoroti ketergantungan pada PLS dalam bidang ini, sementara keberadaan algoritme alternatif, meskipun dalam proporsi yang lebih kecil, menunjukkan eksplorasi berkelanjutan terhadap pembelajaran mesin dan metode statistik untuk meningkatkan kinerja prediktif dan generalisasi model. Khususnya, 19% dari studi yang ditinjau menggunakan algoritme regresi berganda, yang mencerminkan minat yang meningkat pada pendekatan pemodelan hibrida atau komparatif.
4.1 Validasi Eksternal
Validasi eksternal merupakan langkah penting dalam validasi model kemometrik, yang memastikan bahwa model prediktif dapat digeneralisasikan melampaui kumpulan data kalibrasi dan bekerja dengan andal pada data yang tidak terlihat. Namun, 15% artikel yang ditinjau tidak melakukan validasi eksternal sama sekali pada model mereka. Tidak memiliki validasi eksternal yang tepat dan hanya mengandalkan strategi CV dapat menyebabkan estimasi kinerja yang terlalu optimis yang tidak berlaku dalam aplikasi dunia nyata.
Mengenai 85% yang melakukan semacam validasi eksternal dan enam artikel menggunakan lebih dari satu metode, Gambar 6 menyajikan distribusi metode yang digunakan. Sebagian besar penulis yang menggunakan validasi eksternal (29%) tidak mengungkapkan pendekatan validasi eksternal mereka, yang menyoroti kesenjangan dalam transparansi metodologis. Di antara mereka yang menentukan strategi validasi, metode pemisahan acak dan validasi khusus adalah yang paling sering digunakan, diikuti oleh pendekatan yang lebih terstruktur seperti algoritma Kennard–Stone dan SPXY. Perlu dicatat juga bahwa rendahnya penggunaan kumpulan data yang benar-benar independen untuk validasi, meskipun ini, secara umum, adalah pendekatan yang paling direkomendasikan, karena ini adalah pendekatan yang paling realistis untuk estimasi kinerja model [ 7 , 9 ].
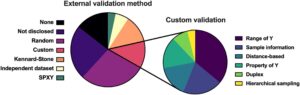
Penggunaan strategi validasi kustom menyarankan upaya untuk menyesuaikan pendekatan validasi dengan karakteristik set data tertentu. Seperti yang ditunjukkan dalam rincian metode validasi kustom (Gambar 6 ), sebagian besar pendekatan ini bergantung pada kriteria mengenai properti lain dari sampel yang tidak dipertimbangkan dalam blok X , seperti rentang atau deviasi standar dari nilai referensi ( y) atau kelas sampel. Sementara metode ini meningkatkan representatif, implementasinya sangat bervariasi, dan standardisasi yang tidak memadai dapat menyebabkan inkonsistensi dalam evaluasi model di seluruh studi. Misalnya, sementara membagi set data secara acak menjadi subset kalibrasi dan validasi adalah pendekatan yang paling umum digunakan, itu pada dasarnya setara dengan melakukan CV k -fold acak tetapi hanya dengan satu partisi. Ini berarti bahwa meskipun menawarkan karakteristik pengambilan sampel acak, itu hanya bergantung pada satu divisi data, membuatnya sangat sensitif terhadap peluang. Akibatnya, itu dapat menghasilkan metrik kinerja yang tidak dapat diandalkan, terutama ketika bekerja dengan set data yang kecil atau tidak terdistribusi secara merata. Dalam kasus semacam ini, akan lebih tepat untuk menggunakan strategi pemisahan data alternatif yang memperhitungkan struktur dan variabilitas himpunan data, di samping CV k -fold acak untuk memperoleh evaluasi model yang lebih kuat dan dapat digeneralisasi.
Untuk meningkatkan keandalan validasi eksternal, beberapa strategi yang dirancang dengan baik dapat digunakan untuk memastikan bahwa set pengujian mewakili kondisi dunia nyata. Salah satu pendekatan yang efektif adalah mempartisi data berdasarkan variabel independen seperti waktu atau kelompok, di mana model diuji pada periode waktu yang sama sekali terpisah, seperti tahun yang berbeda atau kelompok baru. Strategi lain yang berguna adalah mempertahankan proporsi jenis sampel yang sama (misalnya, kelas atau kategori yang berbeda) dalam set kalibrasi dan pengujian, yang mencegah bias yang disebabkan oleh partisi yang tidak seimbang. Selain itu, memastikan bahwa rentang dan distribusi nilai referensi ( y ) terwakili dengan baik di kedua subset membantu mempertahankan evaluasi yang adil, mengurangi risiko model yang terlalu dioptimalkan untuk domain tertentu. Sebagai aturan umum, diperlukan untuk menentukan domain kerja model dan menawarkan set validasi eksternal yang mencakup domain tersebut. Dalam hal ini, dengan menggabungkan strategi validasi terstruktur ini, model dapat dinilai lebih ketat, yang pada akhirnya menghasilkan hasil yang lebih andal dan dapat digeneralisasi.
Sejalan dengan strategi yang digunakan untuk validasi eksternal, Gambar 7 mengilustrasikan distribusi rasio sampel kalibrasi-validasi yang dilaporkan dalam studi yang menggunakan validasi eksternal. Rasio yang paling umum digunakan berkisar antara 2:1 dan 4:1, dengan 3:1 menjadi yang paling sering, yang menunjukkan kecenderungan untuk mengalokasikan sekitar 75% data untuk kalibrasi dan 25% untuk validasi. Rasio di bawah 5:1 jauh lebih jarang, yang menunjukkan bahwa sebagian besar studi menggunakan set validasi berukuran wajar daripada proporsi data minimal untuk penilaian kinerja. Adanya rasio 1:1 dan di atasnya menunjukkan bahwa sejumlah kecil studi menggunakan set validasi sebesar atau lebih besar dari set kalibrasinya, yang dapat terjadi ketika ada ketersediaan sampel yang tinggi.
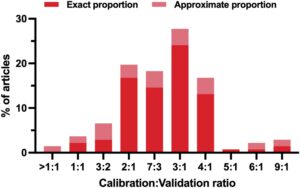
Perbedaan antara proporsi eksak dan perkiraan, yang direpresentasikan oleh berbagai corak dalam histogram pada Gambar 7 , menggambarkan perbedaan dalam cara set kalibrasi dan validasi didefinisikan, dengan beberapa studi yang secara ketat mengikuti rasio yang telah ditentukan sebelumnya dan yang lainnya menggunakan jumlah sampel eksak, mungkin karena penghapusan outlier atau proses kurasi data lainnya. Secara umum, variabilitas yang relatif rendah dalam rasio ini menggarisbawahi bahwa meskipun tidak ada pedoman standar untuk pilihan ini, para praktisi mencapai tingkat konsensus tertentu tentang topik ini.
4.2 Validasi Silang
Di antara 200 artikel yang ditinjau, 83,5% menggunakan beberapa bentuk CV, sedangkan 16,5% sisanya tidak menggunakan CV atau tidak memasukkannya (Gambar 8a ). Tiga artikel menggunakan lebih dari satu metode CV. Metode yang paling sering dilaporkan adalah CV subset acak, diikuti oleh LOO-CV dan CV venetian blind. Namun, sekitar 25% penelitian tidak mengungkapkan metode CV yang digunakan, yang selanjutnya menekankan kurangnya transparansi metodologis dalam praktik validasi. Penggunaan strategi resampling terbatas, hanya enam artikel yang melakukan validasi Monte Carlo, meskipun bermanfaat untuk evaluasi ketahanan model dan penyetelan hiperparameter.
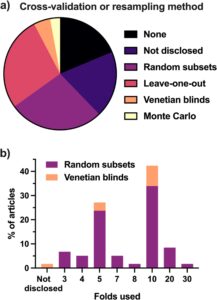
Gambar 8b merinci strategi k -fold yang digunakan oleh 51 penelitian yang menggunakan CV k -fold acak dan delapan penelitian yang menggunakan CV venetian blinds. Nilai k yang paling sering digunakan adalah 10-fold dan lima-fold, yang dapat dijelaskan dengan alasan kepraktisan. Nilai k yang lebih rendah (misalnya, 3, 4 dan 5) dapat membantu menghindari overfitting dengan memastikan set yang lebih substansial dalam setiap iterasi. Nilai k yang lebih tinggi dapat menyebabkan estimasi kinerja model yang terlalu optimis, karena subset validasi menjadi terlalu kecil untuk memberikan penilaian yang andal terhadap generalisasi model.
Menariknya, hanya empat dari penelitian tersebut yang melakukan lebih dari satu iterasi dalam CV; artinya, mereka melakukan pemisahan k- fold acak lebih dari satu kali. Praktik ini menawarkan metrik CV yang lebih kuat karena dihitung melalui beberapa pemisahan data acak dan kemudian dirata-ratakan. Namun, jumlah iterasi yang digunakan juga sangat bervariasi (10, 25 dan 100 iterasi digunakan).
Temuan ini menyoroti perlunya pelaporan CV yang lebih ketat dan transparan. Variabilitas dalam metodologi CV, dikombinasikan dengan kurangnya justifikasi untuk pilihan k -fold dalam banyak penelitian, mempersulit perbandingan langsung antara kinerja model yang dilaporkan. Standarisasi praktik CV dan dorongan kepada penulis untuk membenarkan strategi validasi mereka akan meningkatkan reproduktifitas dan keandalan model kemometrik.
4.3 Pertimbangan Umum
Untuk menilai secara sistematis dan komprehensif ketahanan metodologis praktik validasi dalam literatur yang ditinjau, kerangka kerja tanda keketatan validasi diterapkan. Kerangka kerja ini mengkategorikan studi ke dalam sembilan tingkat kategoris, mulai dari 1 ( paling tidak ketat ) hingga 9 ( paling ketat ), berdasarkan keberadaan dan deskripsi metode CV dan validasi eksternal, seperti yang dijelaskan dalam Tabel 1. Namun, perlu dicatat bahwa ini tidak memastikan validasi yang tepat, karena metodologi terbaik yang akan digunakan dalam setiap studi dapat berubah berdasarkan karakteristik kumpulan data. Gambar 9 menunjukkan distribusi tanda keketatan validasi di seluruh studi yang ditinjau.
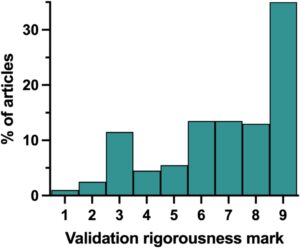
Distribusi tersebut menunjukkan tren yang jelas terhadap skor validasi yang lebih tinggi, dengan proporsi studi terbesar, lebih dari 30% artikel, menerima nilai maksimum (9). Ini berarti bahwa sejumlah besar studi menerapkan strategi validasi CV dan eksternal sekaligus menyediakan deskripsi metodologis untuk studi tersebut, yang mencerminkan komitmen yang semakin besar terhadap praktik validasi yang ketat di antara para praktisi dalam penelitian regresi berbasis NIR untuk aplikasi pangan. Sebagai perbandingan, relatif sedikit studi yang menerima nilai terendah (<6), yang menunjukkan bahwa hanya sebagian kecil artikel yang gagal menerapkan atau mendeskripsikan strategi validasi secara memadai. Namun, artikel dengan nilai 3 lebih sering muncul di antara artikel-artikel tersebut, yang mewakili studi yang menggunakan dan mendeskripsikan metode CV tetapi tidak menggunakan validasi eksternal apa pun, mengandalkan metrik yang disediakan oleh CV untuk menilai generalisasi model, yang sering kali terlalu optimis [ 54 ]. Selain itu, ditemukan bahwa beberapa artikel yang tidak menggunakan CV tetapi melakukan validasi eksternal menggunakan set validasi untuk mengoptimalkan model [ 55 ]; hal ini juga dapat mengakibatkan metrik kinerja yang terlalu pas dan terlalu optimis. Temuan ini menggarisbawahi perlunya penekanan berkelanjutan pada praktik terbaik dalam validasi model untuk meningkatkan reproduktifitas dan keandalan model kemometrik.
Ketika mempelajari tanda keketatan validasi dalam kaitannya dengan ukuran sampel, dalam kaitannya dengan faktor dampak jurnal (IF) yang sesuai, atau IF rata-rata tajuk rencana, tidak ada tren yang jelas muncul (Gambar S1 , S2 , dan S3 ). Hal ini menunjukkan bahwa keketatan validasi tidak secara inheren terkait dengan prestise jurnal atau pengaruh tajuk rencana. Lebih jauh, mengingat hanya beberapa jurnal yang mencapai skor validasi tertinggi, temuan ini menyoroti perlunya semua jurnal dan penerbit untuk menegakkan persyaratan pelaporan validasi yang lebih ketat untuk memastikan transparansi dan keandalan metodologis.
Namun, setelah strategi validasi ditetapkan, metrik kuantitatif diperlukan untuk mengevaluasi model kemometrik, dan di sinilah FoM memainkan peran penting. Metrik ini penting untuk menilai kinerja model, membandingkan berbagai algoritma, dan memastikan reproduktifitas di seluruh studi. Namun, terlepas dari pentingnya, pemilihan dan pelaporan FoM sangat bervariasi di antara studi, yang dapat menghambat perbandingan langsung dan reproduktifitas hasil. Histogram yang menggambarkan distribusi FoM yang dilaporkan dalam 200 studi yang ditinjau ditunjukkan pada Gambar 10. FoM yang paling sering digunakan adalah R dan R 2 , secara kolektif muncul di lebih dari 90% artikel, menggarisbawahi penerimaan luas mereka sebagai indikator utama kecocokan model. Untuk mengevaluasi kinerja model, RMSE sejauh ini merupakan metrik yang paling banyak digunakan, muncul di lebih dari 80% artikel. Metrik lain yang umum digunakan adalah RPD, muncul di hampir 50% artikel, yang berguna untuk menstandardisasi estimasi kesalahan prediksi. Namun, banyak artikel menggunakan RPD untuk mengkategorikan model yang diusulkan secara ‘objektif’ sebagai baik atau buruk berdasarkan skala yang sembarangan, alih-alih menafsirkan hasil secara mendalam, yang dapat mengarah pada kesimpulan yang menyesatkan [ 56 ].
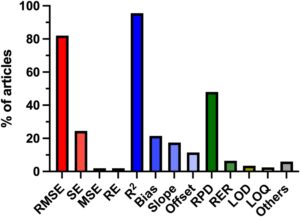
Khususnya, sementara semua studi melaporkan FoM, hanya 33% dari mereka secara eksplisit memberikan rumus matematika untuk setiap metrik yang dilaporkan. Ini juga menyoroti kurangnya transparansi metodologis, terutama dalam FoM, di mana definisinya tidak jelas atau ada lebih dari satu definisi yang tersedia dalam literatur, seperti bias atau LOD dan LOQ [ 45 ]. Selain itu, perangkat lunak yang berbeda dapat menghitung FoM dengan cara yang sedikit berbeda, RMSE, misalnya, dan secara eksplisit memberikan rumus memastikan kejelasan dan memfasilitasi perbandingan yang berarti antara studi. Bias, khususnya, adalah FoM yang dapat didefinisikan dan dihitung dengan berbagai cara, yang menyebabkan kebingungan jika tidak dijelaskan secara eksplisit. Ini dapat merujuk pada perbedaan rata-rata antara nilai prediksi dan nilai referensi, kesalahan sistematis dalam model atau bahkan deviasi kemiringan dari kesatuan dalam analisis regresi.
Selain itu, penggunaan beberapa metrik berbasis kesalahan (misalnya, RMSE, SE, MSE dan RE) dalam satu studi, bahkan secara bergantian seperti yang dilakukan beberapa penulis [ 57 ], mungkin membingungkan dan tidak memberikan nilai tambah yang signifikan, karena metrik ini terkait secara matematis dan menyampaikan informasi yang serupa [ 41 ]. Namun, penulis lain mendasarkan pembahasan hasil hanya pada penggunaan RMSE atau metrik berbasis kesalahan lainnya, alih-alih menawarkan evaluasi komprehensif dari model regresi yang diusulkan, dan sering kali dapat menjadi interpretasi yang bias atau tidak lengkap [ 44 ].
Lebih jauh lagi, terkait dengan FoM, hanya 73,5% dari artikel yang ditinjau menyertakan gambar yang menggambarkan kinerja prediksi model (diprediksi versus referensi atau serupa), yang memungkinkan inspeksi visual karakteristik model. Plot ini penting untuk menilai aspek-aspek utama seperti linearitas, rentang linear, bias dan dispersi residual, memberikan evaluasi kualitas model yang lebih intuitif di luar FoM numerik. Angka-angka ini menjadi lebih relevan tergantung pada pilihan FoM yang dilaporkan, yang mungkin gagal menangkap kekurangan model tertentu [ 58 ]. Khususnya, sementara visualisasi ini penting, penting juga untuk mempertimbangkan apakah menghitung nilai – p dari nilai yang diprediksi versus nilai yang diukur benar-benar diperlukan. Korelasi yang signifikan secara statistik tidak selalu menyiratkan bahwa model tersebut kuat atau berguna, karena signifikansi dapat dipengaruhi oleh ukuran sampel dan faktor-faktor lain yang tidak terkait dengan kinerja prediktif yang sebenarnya.
Secara umum, pendekatan yang lebih terstandarisasi dan komprehensif untuk pelaporan FoM dapat meningkatkan kejelasan dan mencegah redundansi serta informasi yang hilang dalam evaluasi model. Selain itu, seperti yang dijelaskan, ketidakkonsistenan dalam definisi atau ketiadaan definisi tersebut memengaruhi penyebaran dan penerapan praktis hasil, khususnya dalam pengaturan regulasi atau industri di mana definisi yang tepat sangat penting. Menggunakan strategi validasi yang tepat sangat penting; namun, jika penggunaan FoM tidak konsisten atau tidak ketat dan tidak transparan, interpretasi hasil mungkin tidak akurat atau tidak sebanding antara studi, yang berpotensi memberikan kesimpulan yang menyesatkan.
5 Kesimpulan
Tinjauan sistematis ini menyoroti peran penting validasi dalam model regresi kemometrik yang diterapkan pada NIRS untuk analisis pangan. Hasilnya mengungkapkan bahwa regresi PLS adalah pendekatan yang paling umum digunakan, yang mencerminkan kesesuaiannya untuk menangani data spektral kolinear dan kinerjanya yang mapan dalam NIRS. Meskipun pendekatan pembelajaran mesin alternatif telah dieksplorasi pada tingkat yang lebih rendah, kehadirannya dalam beberapa penelitian menunjukkan minat yang semakin besar untuk memperluas jangkauan metodologi yang tersedia.
Lebih jauh, temuan tersebut menekankan pentingnya strategi validasi yang kuat, termasuk validasi CV dan eksternal, untuk memastikan keandalan dan generalisasi model prediktif. Meskipun metode validasi yang agak standar telah diadopsi secara luas, masih terdapat kesenjangan yang signifikan terkait pelaporan strategi validasi dan FoM ini. Untuk meningkatkan ketelitian dan reproduktifitas metode analitis ini, penting untuk mengadopsi pendekatan yang lebih ketat. Studi mendatang harus memastikan strategi validasi komprehensif yang menggabungkan validasi CV dan eksternal, dengan justifikasi yang jelas untuk metode yang dipilih, untuk meningkatkan daya banding antarstudi.
Sementara sebagian besar penelitian menerapkan beberapa bentuk validasi eksternal, banyak yang tidak memberikan rincian eksplisit tentang metodologi validasi mereka, yang berpotensi memengaruhi reproduktifitas hasil mereka. Pemisahan data acak tetap menjadi pendekatan validasi eksternal yang paling umum digunakan, namun keterbatasannya dalam menyediakan penilaian yang benar-benar independen dan kuat menunjukkan perlunya teknik validasi yang lebih terstruktur, seperti set pengujian khusus atau yang sepenuhnya independen. Demikian pula, sementara CV digunakan dalam sebagian besar penelitian, implementasinya sangat bervariasi, dengan pelaporan parameter k -fold, jumlah iterasi, dan metode resampling yang tidak konsisten.
Penilaian FoM lebih jauh menggarisbawahi perlunya praktik pelaporan yang lebih ketat. Sementara metrik berbasis korelasi seperti R 2 dan metrik kesalahan seperti RMSE digunakan secara luas, definisi dan penerapan FoM lain yang tidak konsisten, terutama yang memiliki definisi yang mungkin berbeda dan belum distandarisasi, seperti bias atau LOD, mempersulit perbandingan langsung di seluruh studi. Seringnya penghilangan rumus matematika untuk metrik yang ambigu ini semakin memperburuk masalah ini. Selain itu, meskipun penting dalam menilai kinerja model, representasi visual dari kinerja model tidak ada dalam sejumlah besar studi, membatasi kemampuan untuk mengevaluasi secara kritis model kemometrik yang diusulkan. Standardisasi FoM, termasuk definisi eksplisit, akan membantu mengurangi inkonsistensi dalam evaluasi kinerja, dan penyertaan penilaian kinerja visual, seperti plot yang diprediksi versus yang diamati, akan memfasilitasi evaluasi kualitas model yang lebih intuitif.
Meningkatnya ketergantungan pada model kemometrik berbasis NIR dalam analisis pangan menggarisbawahi perlunya validasi yang ketat untuk menjaga integritas ilmiah dan penerapan praktis. Dengan menerapkan praktik validasi yang terstandarisasi dan transparan, bidang ini dapat bergerak menuju penerapan yang lebih luas, mendorong pengembangan model prediktif yang lebih andal dan dapat digeneralisasi untuk aplikasi kualitas dan keamanan pangan.